Chuleta de purrr
¿Qué es purrr?
purrr es un paquete que permite realizar bucles de una manera no convencional, diferente, quizás más fácil de entender, al tratarlos como funciones naturales.
Se trata de una librería creada por RSTUDIO dentro del universo tidyverse, cada vez más completo y poderoso. Este paquete purrr entra en el campo de programación funcional. Básicamente trata de sustituir código de programación base por órdenes “humanas”, es decir con funciones.
Para hacernos una idea purrres como una extensión, generalización y mejora de las funciones lapply de R que son tan poderosas. En realidad hacen lo mismo de estas funciones, pero purrr tiene algunas ventajas, para mi la principal es que es sintáctica-mente estable, y más sencillo de recordar y completar, además tiene la opción de usar la función tubería %>% y muchas simplificaciones de código de tidyverse, que las lapply (sapply, tapply y mapply) no tienen. Por contra su ejecución es más lenta que estas funciones.
Instalación
La instalación de purrr es sencilla, y se puede hacer en solitario o como parte de tidyverse.
# esta es la forma mas sencilla
install.packages("tidyverse")
# AComo alternativa puedes cargar el paquete solo
install.packages("purrr")
# O la versión de desarrollo en GitHub:
# install.packages("devtools")
devtools::install_github("tidyverse/purrr")Función básica: map()
La función básica de purrr es map(lista, funcion). El resultado es simple, coge cada elemento de la lista de entrada,de uno en uno, y le aplica la función que ponemos de segundo argumento, al final da otra lista, pero - y aquí viene una de las mejoras respecto a apply- existen apellidos de map_* que permiten obtener directamente el resultado en otro formato, como por ejemplo:
map_lgl()salida como vector lógico.map_int()salida como vector de enteros.map_dbl()número doble.map_chr()vector de texto.map_df()una tabla data frame.
Otra cosa importante de la función es que se puede usar de dos formas: la simple map(lista, funcion) y la compleja, pero más completa map(lista, ~funcion(.x)).
Este formato especifica con .x la variable que toma el valor de cada elemento de la lista, pero ¡ojo! que antes hay que poner el símbolo ~. Además podemos usar la función tubería dentro del argumento. Veamos un ejemplo que es más claro:
require(tidyverse)
# creamos una lista
lista.compra<-list(comida=c("manzanas", "peras", "chocolate", "pollo"),
bebida=c("leche","vino"),
numtef=c(912345678,912783782,939287833))
#Calculamos el numero de elementos de cada sublista
map_int(lista.compra, length)## comida bebida numtef
## 4 2 3 #o tambien así usando la forma compleja:
map_int(lista.compra, ~.x %>% length())## comida bebida numtef
## 4 2 3 # Ejemplo:
# seleccionamos solo el segundo elemento de cada elemento de la lista
map(lista.compra, ~.x[2])## $comida
## [1] "peras"
##
## $bebida
## [1] "vino"
##
## $numtef
## [1] 912783782Sin la notación simplificada este último ejemplo requeriría hacer una función específica. Sin embargo la notación de purrr permite hacer cosas muy complicadas con poco código.
Recordatorio de listas
Para manejar purrr al máximo es mejor dar un breve repaso al tipo de datos lista, que en R es el objeto más completo pues actúa como una colección de cosas variadas.
Para seleccionar un elemento dentro de una lista tenemos que acceder con doble corchete [[..]].
# el segundo elemento
lista.compra[[2]]## [1] "leche" "vino" # el 1er elemento de la lista segunda
lista.compra[[2]][1]## [1] "leche"Nombres de una lista
En lugar de los dobles corchetes, se puede hacer uso de nombres, en caso de que tengan nombres. En ese caso puede accederse a ellos igual que como si se tratase de un data frame con el símbolo $_nombre:
# la lista anterior tenia nombres:
names(lista.compra)## [1] "comida" "bebida" "numtef" # acedemos al segundo valor del elemento de la lista llamado comida
lista.compra$bebida[1]## [1] "leche"Las listas que usamos en el mundo real suelen ser anidadas, es decir listas de listas, muchas generadas tras la lectura de bases de datos o consultas a APIS que dan resultados en JSON. En muchos de estos casos la lista viene sin nombre, pero hay un campo dentro de cada elemento lista que nos puede valer de nombre válido.
Por ejemplo, la lista de ejemplo de usuarios de gitHub que viene en el paquete repurrrsive. Vamos a ponerle nombre a los objetos lista, pues hay un campo llamado name que nos vale y así facilitamos el acceso a los datos:
library(repurrrsive)
#cargamos los dato
data(gh_users)
# Checamos si tiene nombre
names(gh_users)## NULL # Como no tiene leemos el subelemento name
# de cada elemento de la lista y lo asignamos como nombre.
map(gh_users, ~.x[["name"]])## [[1]]
## [1] "Gábor Csárdi"
##
## [[2]]
## [1] "Jennifer (Jenny) Bryan"
##
## [[3]]
## [1] "Jeff L."
##
## [[4]]
## [1] "Julia Silge"
##
## [[5]]
## [1] "Thomas J. Leeper"
##
## [[6]]
## [1] "Maëlle Salmon" gh_users_nom <- gh_users %>%
set_names(map_chr(gh_users, "name"))
# ahora ya tiene nombres:
names(gh_users_nom)## [1] "Gábor Csárdi" "Jennifer (Jenny) Bryan"
## [3] "Jeff L." "Julia Silge"
## [5] "Thomas J. Leeper" "Maëlle Salmon" #accedemos con el nombre
gh_users_nom$`Julia Silge`[3]## $avatar_url
## [1] "https://avatars.githubusercontent.com/u/12505835?v=3"walk()
Las listas son difíciles de ver, por eso en purrr hay un comando llamado walk() que las imprime de manera resumida y simplificada:
lista3<-list(10:1, "hola", 123:133, c(T,F,F,F,T))
# forma normal de impresión
lista3## [[1]]
## [1] 10 9 8 7 6 5 4 3 2 1
##
## [[2]]
## [1] "hola"
##
## [[3]]
## [1] 123 124 125 126 127 128 129 130 131 132 133
##
## [[4]]
## [1] TRUE FALSE FALSE FALSE TRUE # Forma simplificada con walk()
walk(lista3, print)## [1] 10 9 8 7 6 5 4 3 2 1
## [1] "hola"
## [1] 123 124 125 126 127 128 129 130 131 132 133
## [1] TRUE FALSE FALSE FALSE TRUEmap2() y pmap()
La función map() nos permite usar una lista como secuenciador del bucle, pero si necesitamos más de una lista, o lo que es lo mismo, hacer un bucle anidado, debemos usar otra función de purrr llamada map2(lista1, lista2, función(.x, .y)).
Si como entrada necesitamos más de dos listas usaremos la función genérica pmap(input_list, funcion), cuyo argumento de entrada es una lista de listas llamada input_list que tenemos que definir antes de llamar a pmap()
Ejemplo: generacion de series sintéticas
Para mi, las funciones map() son útiles para hacer datos de simulación y prueba, por ejemplo pongamos que necesito datos de gastos e ingresos de unas personas y no tengo, pero si tango los valores medios de esos datos, valor medio de ingresos, de gastos al mes y la variación, pues me invento una serie:
# Ejemplo de generacion de datos simulados a partir de medias
require(purrr)
# lista de los valores medios que conozco
input_list <- list(
nombre= c("Juan", "Ana", "Pepe"),
ingresos.mes = c(1000, 1500, 3000),
gastos.mes = c(600, 670, 1800),
variacion= c(200, 100, 1000))
str(input_list)## List of 4
## $ nombre : chr [1:3] "Juan" "Ana" "Pepe"
## $ ingresos.mes: num [1:3] 1000 1500 3000
## $ gastos.mes : num [1:3] 600 670 1800
## $ variacion : num [1:3] 200 100 1000 # Valores simulados
simdata <- pmap(input_list,
function(ingresos.mes,gastos.mes, variacion, nombre)
data.frame(ingresos=rnorm(mean=ingresos.mes,
n= 48,
sd= variacion/3),
gastos = rnorm(mean=gastos.mes,
n= 48,
sd= variacion),
persona = nombre))
head(simdata[[1]])## ingresos gastos persona
## 1 1036.9554 499.9461 Juan
## 2 925.2721 702.7358 Juan
## 3 966.4187 778.1069 Juan
## 4 923.3468 382.9528 Juan
## 5 954.6797 619.7367 Juan
## 6 1094.4298 590.2776 Juan # Unimos las listas generadas con dplyr
# en un solo dataframe con la funcion bind_rows
require(dplyr)
dt_gastos<-bind_rows(simdata)
require(ggplot2)
# ggplot(dt_gastos) +aes(x=persona,y=ingresos)+
# geom_col(aes(fill=persona))
ggplot(dt_gastos) +aes(x=ingresos,fill=persona)+
labs(title = "Ingresos mensuales por persona")+
geom_histogram()+geom_rug()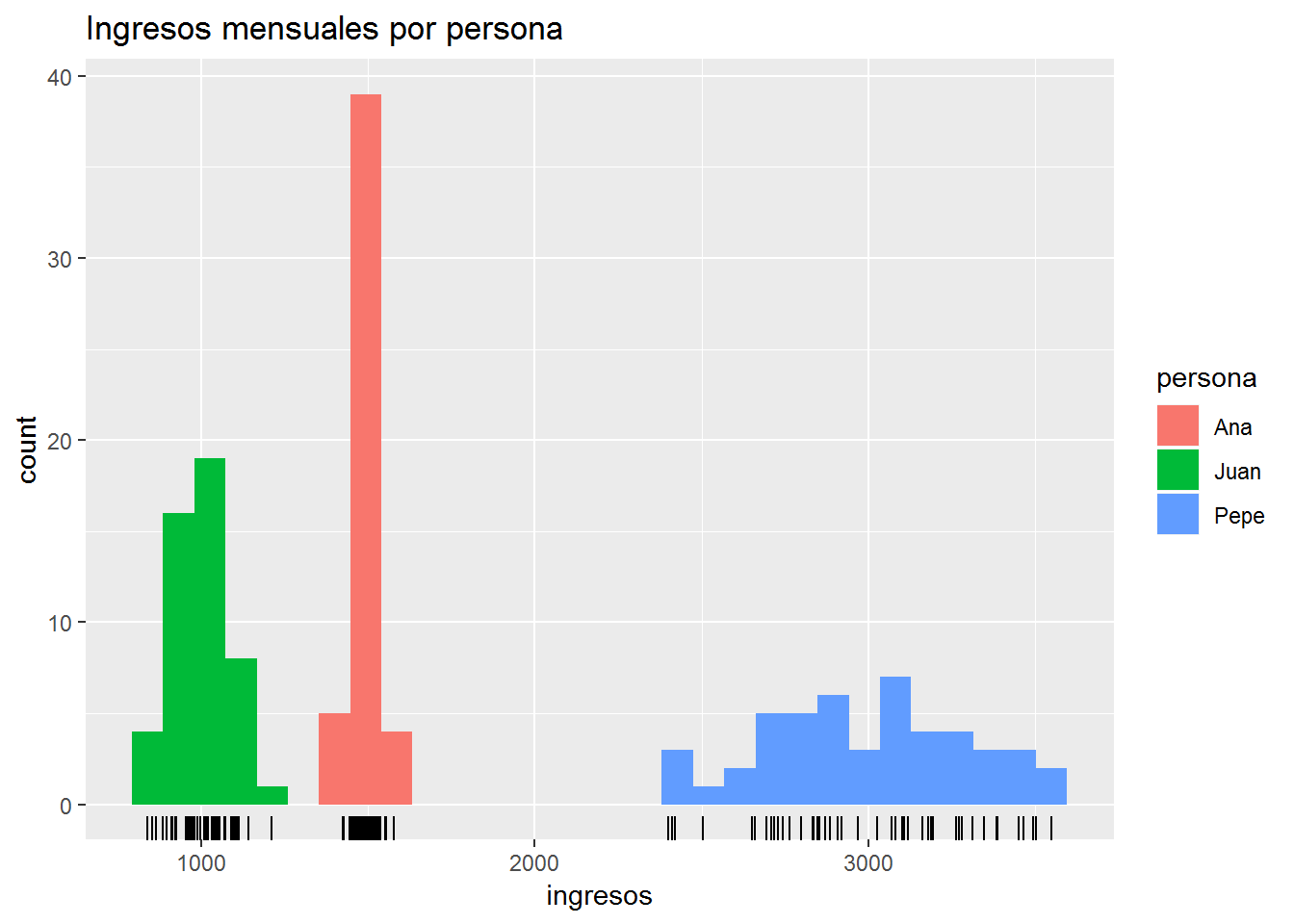
ggplot(dt_gastos) +aes(x=persona,y=ingresos, fill=persona)+
labs(title = "Ingresos medios por persona")+
labs(subtitle = "a partir de los datos generados")+
labs(y = "ingreso medio al mes en €")+
stat_summary(fun.y = "mean", geom = "bar")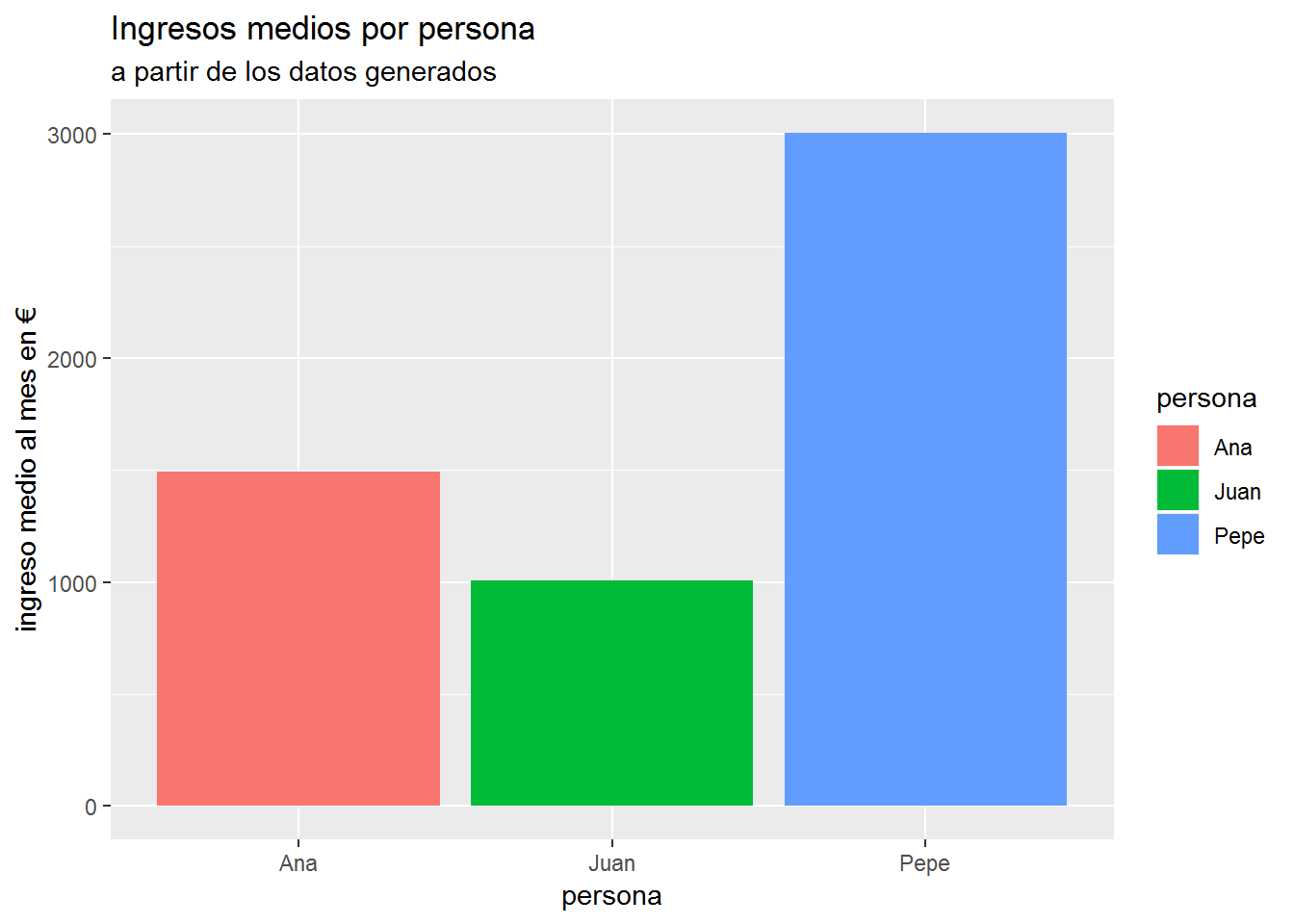
Ejemplo con map2()
Con map2 podemos usar la notación simplificada de función es decir .x e .y. En este caso queremos generar otra serie aleatoria de muestreo. Tenemos datos de caudales medios de 3 ríos y de su nombre.
Vamos a generar automáticamente una serie de 10 datos de cada río.
# Muestras de caudal de tamaño diferente
caudales_medios <- map(c(5,100,12),~.x)
# Localizaciones
cuenca <- list("Norte", "Este","Sur")
# pongo los nombres
set_names(caudales_medios,cuenca)## $Norte
## [1] 5
##
## $Este
## [1] 100
##
## $Sur
## [1] 12 # Map over two arguments: sites and means
l_caudales <- map2(cuenca,caudales_medios, ~data.frame(cuenca = .x,
caudales = rnorm(mean = .y, n = 10, sd = .y/5)))
# para unir las listas creadas en un solo dataframe usaremos dplyr
require(dplyr)
dt_caudales<-bind_rows(l_caudales)
ggplot(dt_caudales) +aes(x=cuenca,y=caudales, color=cuenca)+
labs(title = "Caudales medios")+
labs(subtitle = "a partir de los datos generados")+
labs(y = "Caudal en m3/s")+
geom_boxplot()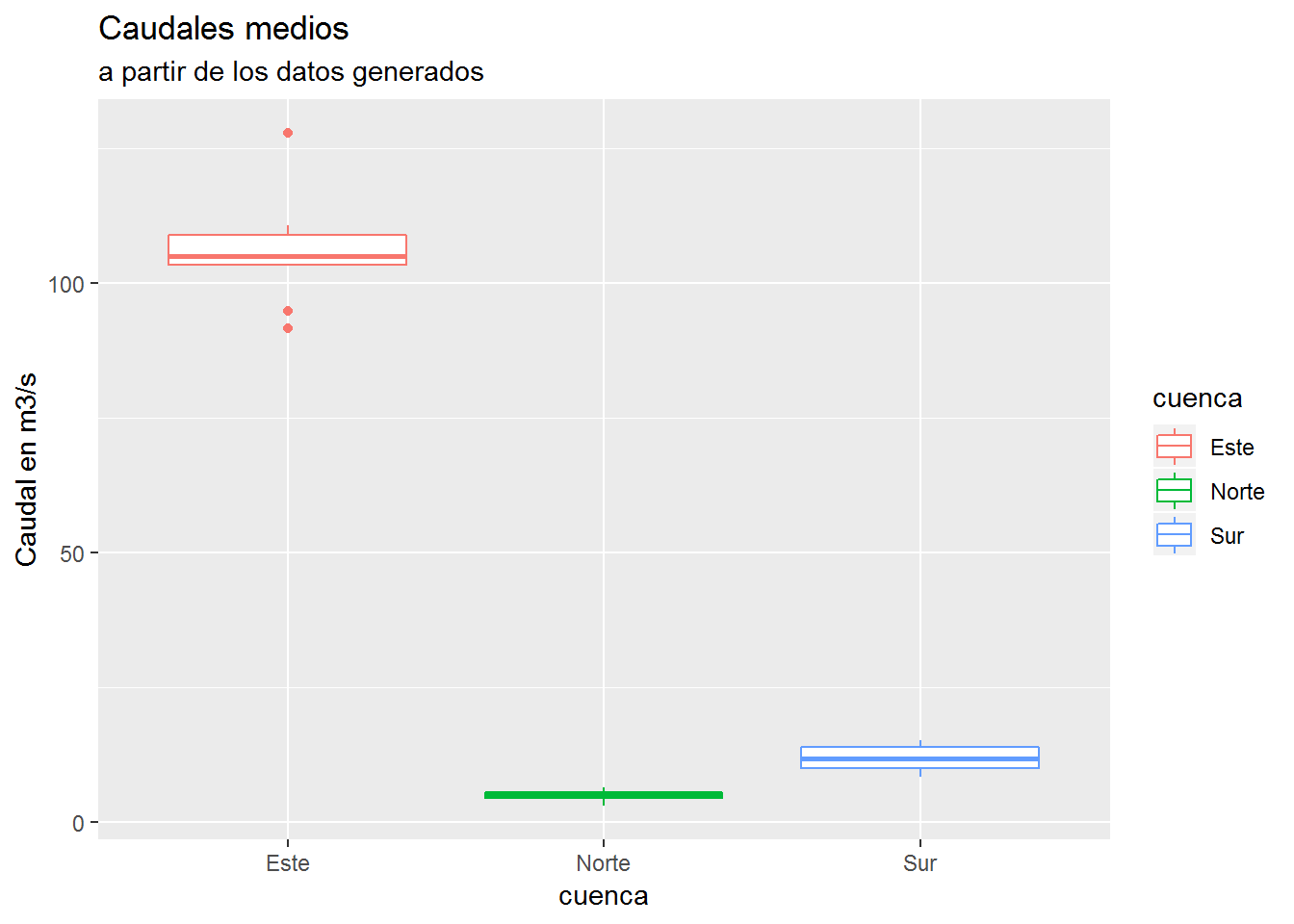
Manejo de errores safely() y possibly()
Si algún elemento de la lista no es del tipo correcto para la función, map va a dar error. En listas grandes localizar el error es difícil, por eso han creado las funciones safely() y possibly(), que localizan los errores y sustituyen los resultados por un valor por defecto.
Si añadimos safely() a la función map(), se crea una lista que contiene resultados y errores, mientras que possibly() sustituye directamente los errores por un valor por defecto, dando una salida limpia.
La función tranpose(), nos sirve para pasar de una lista de listas a otra cosa más fácil de representar:
# Ejemplo de uso de safely
require(tidyverse)
# Uso de possibly
list(-20, 10, 100) %>%
map_dbl(possibly(log, NA_real_))## [1] NaN 2.302585 4.605170 # Uso de possibly
a<-list("fernando", 10, 100) %>%
map(safely(log, NA_real_)) %>% transpose()
# vemos el resultado
a$result## [[1]]
## [1] NA
##
## [[2]]
## [1] 2.302585
##
## [[3]]
## [1] 4.60517 # Vemos el error
a$error## [[1]]
## <simpleError in .Primitive("log")(x, base): non-numeric argument to mathematical function>
##
## [[2]]
## NULL
##
## [[3]]
## NULLConsultas en listas
Otro de los usos habituales de purrr es para hacer consultas sobre listas. Vamos a ver un ejemplo de consultas a la lista gh_users que trae de ejemplo el paquete repurrrsive. Esta lista contiene mucha información de varios usuarios de la plataforma gitHub. Mediante código vamos a responder a algunas preguntas como:
- ¿quien se unió primero a gitHub?
- ¿Cuál de los usuarios tiene más repositorios públicos?
- hacer una gráfica con los seguidores de cada usuario
esto lo haremos simplemente seleccionando el campo de la lista que contiene los datos y ordenando el vector resultado:
require(repurrrsive)
#cargamos la lista en memoria
data(gh_users)
# 1. ¿quien se unió primero a gitHub?
map_chr(gh_users, ~.[["created_at"]]) %>%
set_names(map_chr(gh_users, "name")) %>%
sort()## Jennifer (Jenny) Bryan Gábor Csárdi Jeff L.
## "2011-02-03T22:37:41Z" "2011-03-09T17:29:25Z" "2012-03-24T18:16:43Z"
## Thomas J. Leeper Maëlle Salmon Julia Silge
## "2013-02-07T21:07:00Z" "2014-08-05T08:10:04Z" "2015-05-19T02:51:23Z" # 2. ¿Cuál de los usuarios tiene más repositorios públicos?
map_int(gh_users, ~.[["public_repos"]]) %>%
set_names(map_chr(gh_users, "name")) %>%
sort()## Julia Silge Maëlle Salmon Gábor Csárdi
## 26 31 52
## Jeff L. Thomas J. Leeper Jennifer (Jenny) Bryan
## 67 99 168# 3- grafica con el numero de seguidores vs repos publicas
ggplot(data = map_df(gh_users, ~data_frame(
public_repos =.x[["public_repos"]],
followers = .x[["followers"]],
nombre = .x[["name"]])),
aes(x = public_repos, y = followers))+
geom_point(mapping=aes(color = nombre),size=7)+
geom_text(aes(label=nombre),
hjust = 1, nudge_x = 0,size=4)+
labs(title = 'Seguidores vs public_repo')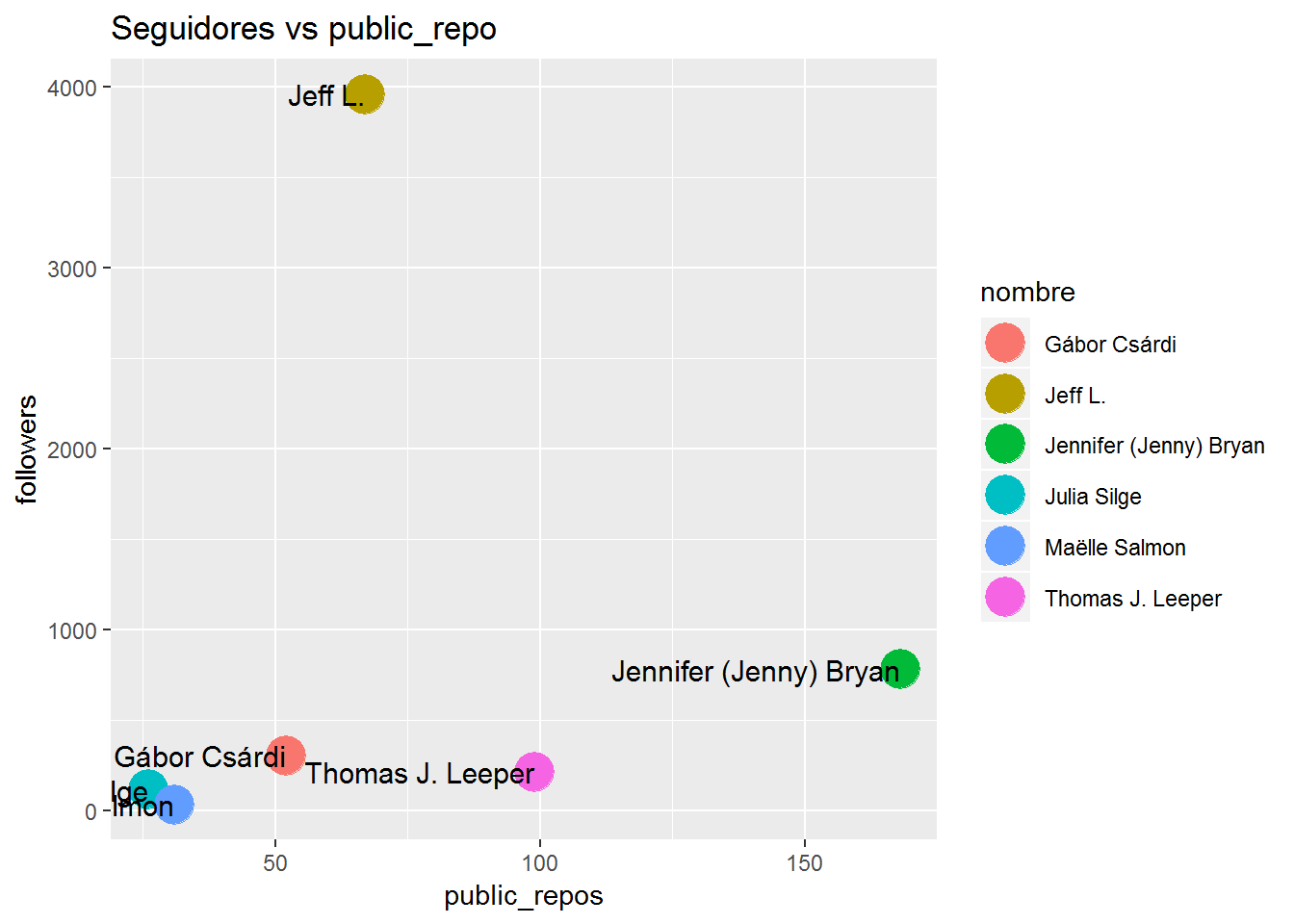
También hay funciones para hacer resúmenes de los datos (numéricos) como summary o otras funciones de selección como select_if()
# llista de ejemplo
per_df <- list(peso=rnorm(10,mean=80,sd=20),
altura=rnorm(10,mean=180,sd=20))
summary(per_df)## Length Class Mode
## peso 10 -none- numeric
## altura 10 -none- numericEjemplo Star Wars
Vamos a usar de ejemplo una base de datos en formato lista, sacada de la web https://swapi.co/ que ha recopilado TODOS los datos de las películas de la saga Star Wars y creado una API para su consulta… qué cosas hacen los frikis.
No tenemos que hacer las consultas a la API, pues en el paquete repurrrsive han incluido varias de ejemplo: sw_people, sw_films, sw_planets, sw_species, sw_vehicles y sw_starships.
Cada una de estas listas contiene la información completa de los personajes, películas, planetas, especies, vehículos y naves espaciales que aparecen en todas las pelis de la saga.
Echemos un vistazo, a la lista de películas sw_films:
#require(purrr)
require(tidyverse)
require(repurrrsive)
# vemos si tiene nombres.. NO
names(sw_films)## NULL #Vemos cuantos elementos tiene
length(sw_films)## [1] 7 # vemos cuantos elementos tiene cada elemento principal
lengths(sw_films)## [1] 14 14 14 14 14 14 13 # vemos uno de esos subelementos de 14 campos a ver que tienen
summary(sw_films[[1]])## Length Class Mode
## title 1 -none- character
## episode_id 1 -none- numeric
## opening_crawl 1 -none- character
## director 1 -none- character
## producer 1 -none- character
## release_date 1 -none- character
## characters 18 -none- character
## planets 3 -none- character
## starships 8 -none- character
## vehicles 4 -none- character
## species 5 -none- character
## created 1 -none- character
## edited 1 -none- character
## url 1 -none- character # vemos lo que contiene el primero
#walk(sw_films[[1]],print))
# comprobamos que los subelementos tienen nombre
names(sw_films[[1]])## [1] "title" "episode_id" "opening_crawl" "director"
## [5] "producer" "release_date" "characters" "planets"
## [9] "starships" "vehicles" "species" "created"
## [13] "edited" "url"Con esto hemos echado un vistazo y sabemos cómo está estructurada la lista de películas. Ahora vamos a sacar el jugo, extraeremos una tabla con los datos del nombre de la película y el de los actores que participan en ella. De esta forma podremos hacer alguna gráfica interesante. Usaremos la función pipe y una nueva unnest() muy interesante.
unnest() nos convierte una lista de 2 elementos y misma longitud en cada uno de subelementos (7) a una tabla que coge una fila por cada combinación uno a uno de elementos.
De la lista de actores sacaremos los campo nombre y url que nos vale para hacer un inner_join a la tabla de películas.
# vamos a hacer una data frame a partir de la lista
# primero extraemos la lista de títulos de las peliculas que están en el campo title
# despues creamos un nuevo campo y extraemos de cada pelicula los actores que han participado
sw_df <- data.frame(pelicula = map_chr(sw_films, ~.x$title)) %>%
mutate(pelicula, actor = map(sw_films, ~.x$characters))%>%
unnest()
# De la lista sw_people sacamos la correspondencia entre url y nombre del actor
sw_actores <- map_df(sw_people, `[`, c("name", "url"))
# juntamos las tablas
sw_dt<-inner_join(sw_df, sw_actores, by = c("actor" = "url"))
str(sw_dt)## 'data.frame': 173 obs. of 3 variables:
## $ pelicula: Factor w/ 7 levels "A New Hope","Attack of the Clones",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ actor : chr "http://swapi.co/api/people/1/" "http://swapi.co/api/people/2/" "http://swapi.co/api/people/3/" "http://swapi.co/api/people/4/" ...
## $ name : chr "Luke Skywalker" "C-3PO" "R2-D2" "Darth Vader" ... # borramos la segunda columna, pues las url ya no nos valen
sw_dt<-sw_dt[-2]
#cambiamos de nombre
colnames(sw_dt)<-c("pelicula", "actor")
class(sw_dt)## [1] "data.frame" str(sw_dt)## 'data.frame': 173 obs. of 2 variables:
## $ pelicula: Factor w/ 7 levels "A New Hope","Attack of the Clones",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ actor : chr "Luke Skywalker" "C-3PO" "R2-D2" "Darth Vader" ... # ahora podemos sacar algunas gráficas
ggplot(sw_dt, aes(x = actor,fill = pelicula)) +
geom_histogram(stat = "count",alpha = 0.6)+
labs(x = 'actor', y = 'nº peliculas') +
labs(title='Numero de peliculas que hace cada actor de Star Wars')+
theme(axis.text.x = element_text(angle = 90, hjust = 1,size=6))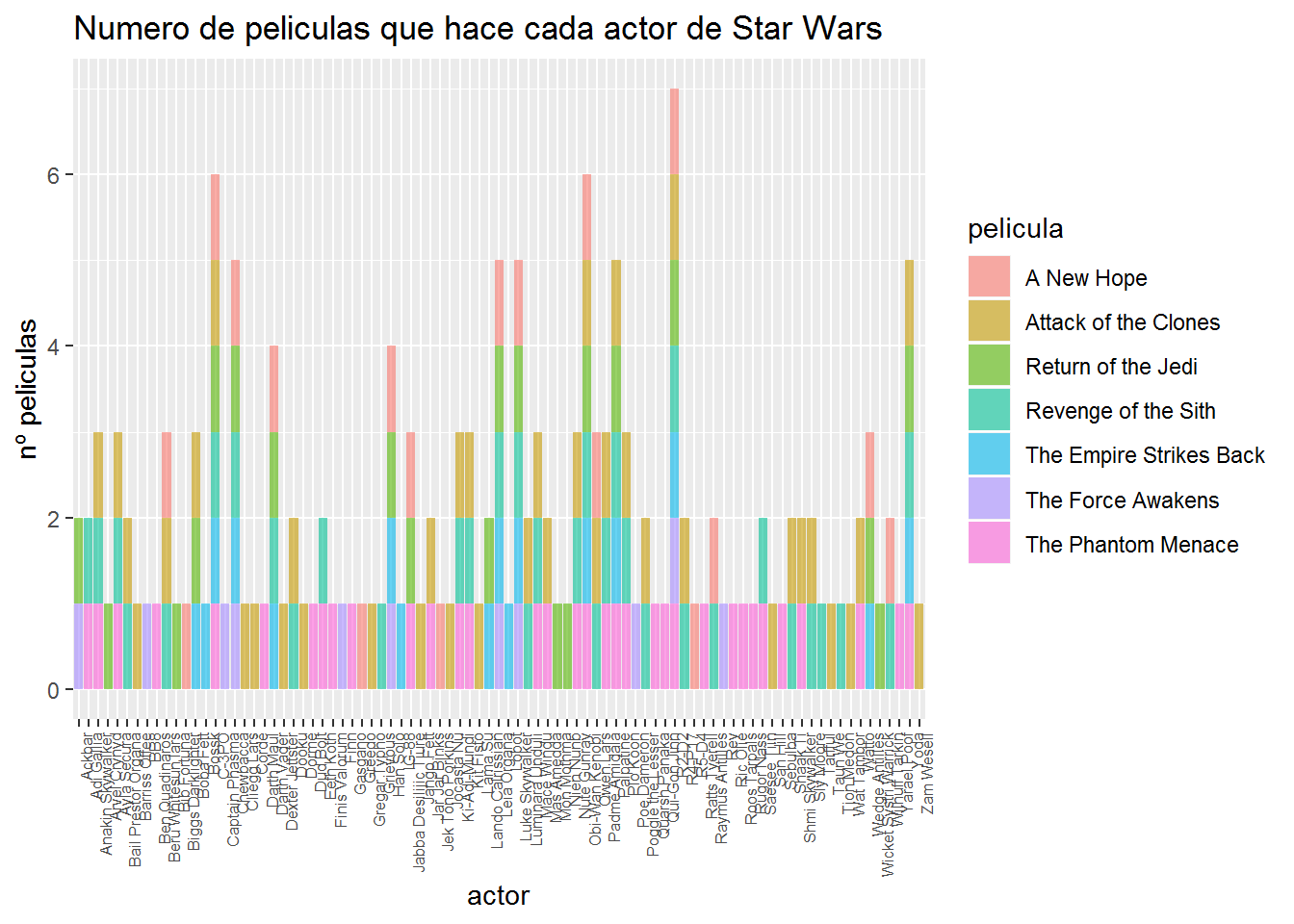
# pero quiero ver solo los actores principales los que aparecen en 2 o mas pelis
# ad_count es una manera simplificada de group_by y tally
# ver aqui https://dplyr.tidyverse.org/reference/tally.html
#a<- sw_dt %>% group_by(actor)%>% tally()
# añadimos una columna con el num de veces total que aparece cada
sw_dt<-sw_dt %>% add_count(actor)
# pintamos ahora solo los actores que participan en mas de 2 peliculas
ggplot(sw_dt[sw_dt$n>2,], aes(x = actor,fill = pelicula)) +
geom_histogram(stat = "count",alpha = 0.6)+
labs(x = 'actor', y = 'nº peliculas') +
labs(title='Actores en las peliculas de Star Wars')+
theme(axis.text.x = element_text(angle = 90, hjust = 1,size=8))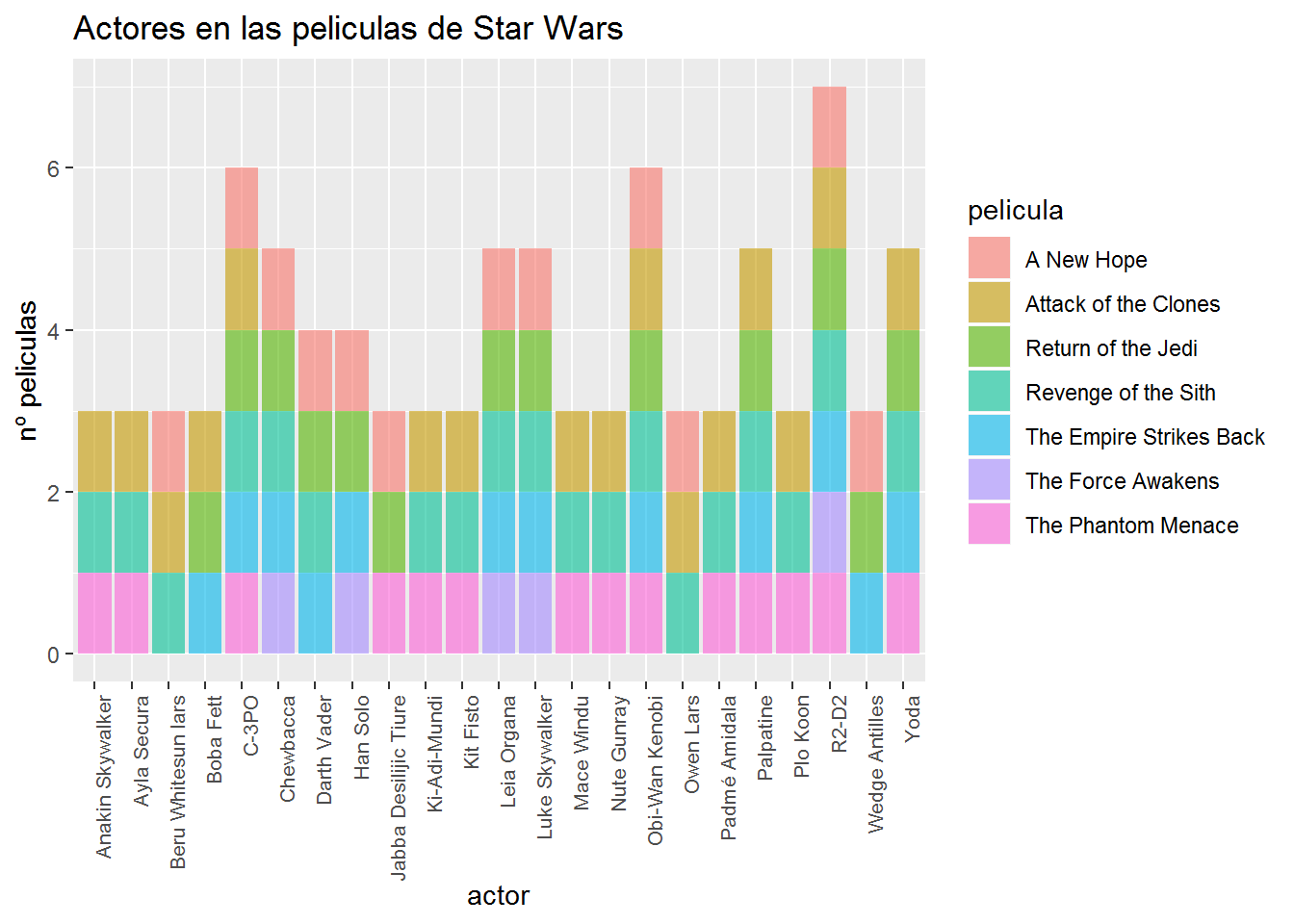
# Ahora pintamos una gráfica con el
# numero de actores que participan en cada pelicula
ggplot(sw_dt, aes(x = pelicula,fill = pelicula)) +
geom_histogram(stat = "count",alpha = 0.6)+
labs(x = 'Película', y = 'nº actores') +
labs(title='nº de actores por pelicula de Star Wars')+
theme(legend.position = "none")+
theme(axis.text.x = element_text(angle = 90, hjust = 1))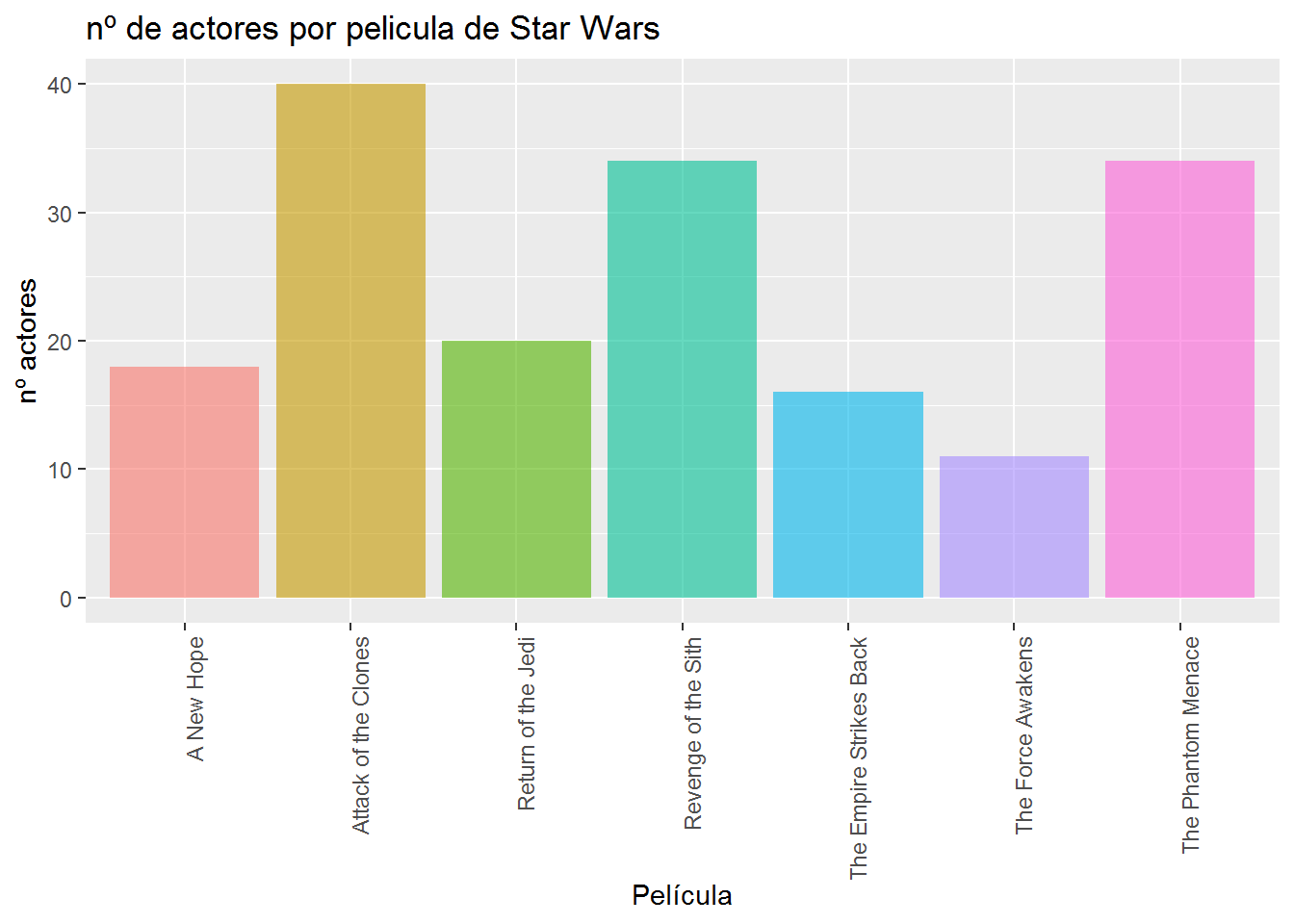
Vamos a dar otra vuelta sobre las listas de Star Wars, ahora sacaremos de la lista de actores datos físicos altura, colore de pelo, haremos alguna gráfica resumen:
# Añadimos más información a la tabla sacando los datos físicos
# peso, altura, color de pelo, año nacimiento, nombre y url
#de los actores desde sw_people
#str(sw_dt)
dt_fisicos <- map_df(sw_people, `[`, c("height", "mass","hair_color","birth_year","name"))
# resultados
head(dt_fisicos)## # A tibble: 6 x 5
## height mass hair_color birth_year name
## <chr> <chr> <chr> <chr> <chr>
## 1 172 77 blond 19BBY Luke Skywalker
## 2 167 75 n/a 112BBY C-3PO
## 3 96 32 n/a 33BBY R2-D2
## 4 202 136 none 41.9BBY Darth Vader
## 5 150 49 brown 19BBY Leia Organa
## 6 178 120 brown, grey 52BBY Owen Lars # Juntamos los datos con la tabla anterior sw_dt, ya que coinciden el campo actor y name
sw_dt1 <- inner_join(sw_dt, dt_fisicos, by = c("actor" = "name"))
head(sw_dt1)## # A tibble: 6 x 7
## pelicula actor n height mass hair_color birth_year
## <fct> <chr> <int> <chr> <chr> <chr> <chr>
## 1 A New Hope Luke Skywalker 5 172 77 blond 19BBY
## 2 A New Hope C-3PO 6 167 75 n/a 112BBY
## 3 A New Hope R2-D2 7 96 32 n/a 33BBY
## 4 A New Hope Darth Vader 4 202 136 none 41.9BBY
## 5 A New Hope Leia Organa 5 150 49 brown 19BBY
## 6 A New Hope Owen Lars 3 178 120 brown, grey 52BBY # vemos que las columnas peso y altura son de texto, por lo que transformamos a numero
sw_dt1<-sw_dt1 %>% mutate(altura = as.numeric(height), peso = as.numeric(mass))
# numero de actores por película
sw_dt1 %>% group_by(pelicula) %>% tally()## # A tibble: 7 x 2
## pelicula n
## <fct> <int>
## 1 A New Hope 62
## 2 Attack of the Clones 97
## 3 Return of the Jedi 70
## 4 Revenge of the Sith 105
## 5 The Empire Strikes Back 63
## 6 The Force Awakens 33
## 7 The Phantom Menace 83 # peso medio de los actores en cada pelicula
pesosxfilm<-aggregate(peso ~ pelicula, sw_dt1, mean)
pesosxfilm## pelicula peso
## 1 A New Hope 80.56250
## 2 Attack of the Clones 70.70345
## 3 Return of the Jedi 70.95000
## 4 Revenge of the Sith 78.52414
## 5 The Empire Strikes Back 81.01250
## 6 The Force Awakens 72.16667
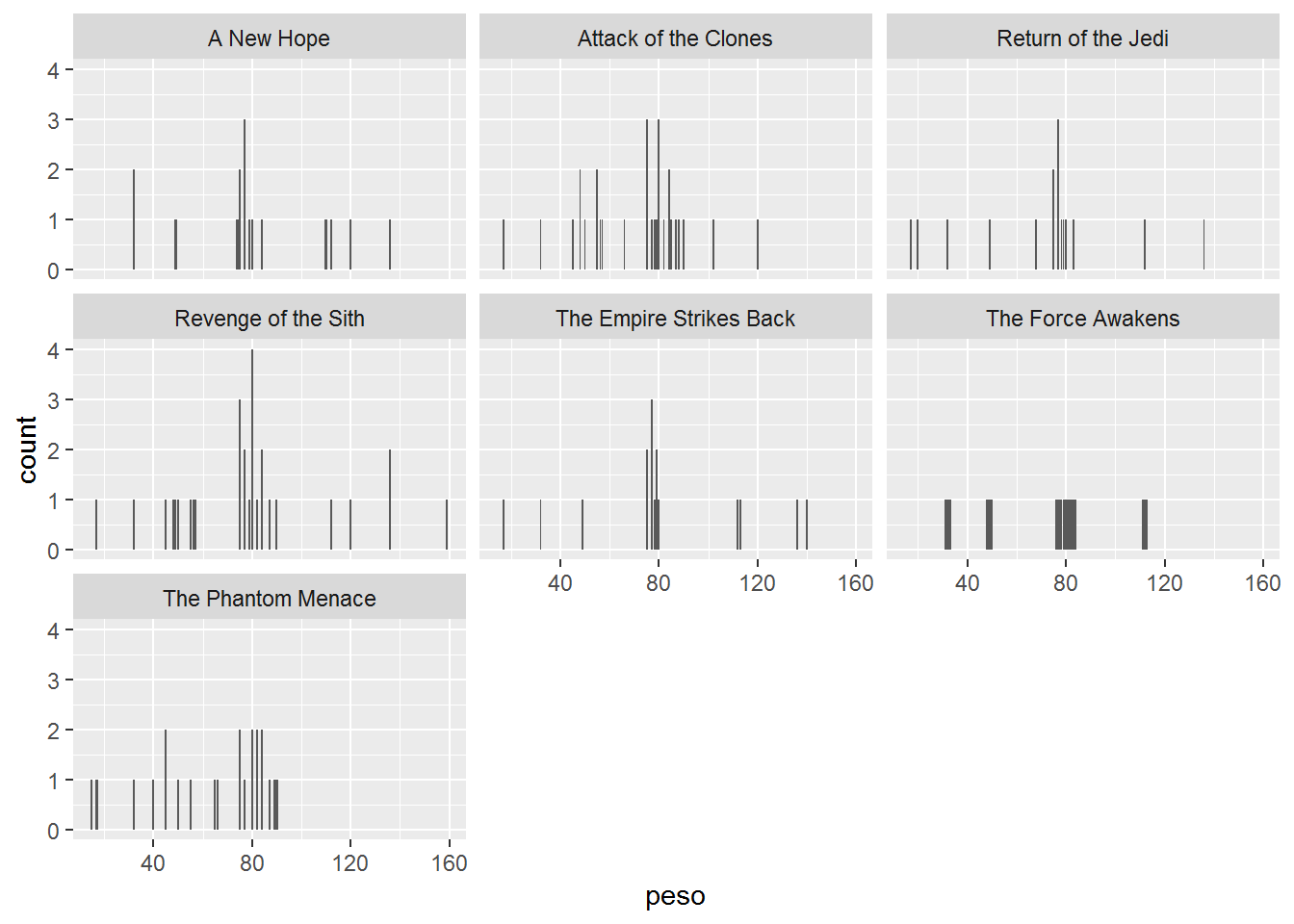
## 7 The Phantom Menace 64.31818 # Plot the heights, faceted by film title
ggplot(sw_dt1, aes(x = peso)) +
geom_histogram(stat = "count") +
facet_wrap(~ pelicula)