Bases de datos con R
Usar una base de datos para nuestros programas o análisis de datos en R es bastante más fácil de lo parece y es una forma interesante de almacenar los datos y acceder a ellos de manera estructurada. Sinceramente creo que la mayoría no lo usa por puro desconocimiento, pero los datos en bases de datos están mejor guardados, se gestionan mejor y es más fácil compartirlos que en ficheros, así que vamos a poner un ejemplo simple de uso que os anime y os sirva para vuestros propios proyectos.
Ficheros nativos de R para datos
Antes de entrar en el tema de bases de datos, lo normal es que usemos para almacenamiento de los datos ficheros tipo *.csv por ejemplo, pero R tiene dos formatos nativos para almacenar en local datos que son interesantes se trata de los tipos: *.RData y *.RDS con la ventaja de ser muy compactos y de acceso súper rápido.
La diferencia entre ambos es que el formato .RData guarda varios objetos, mientras que los .RDS solo pueden almacenar uno, aunque si ese uno es una lista … pues tienes ya varios objetos.
Su uso es muy sencillo, basta con usar la función save() y load() para los .RData, y los datos se nos cargan en memoria con el mismo nombre que tenían:
# Guardamos todos los objetos de la sesión
save(list = ls(all = TRUE), file= "./datos/todos.RData")
# para cargarlos después usamos load
load("./datos/datos/todos.RData")El caso de .RDS es parecido, con la ventaja de que al importar le podemos dar nombre, cosa que con .RData no se puede ya que lo importa todo tal cual se almacenó :
# guardar un objeto como rds
write_rds(mi_objeto, "datos/variable.rds")
# importar un objeto RDS
objeto1 <- readRDS("datos/variable.rds")Como vemos almacenar los datos de trabajo en estos formatos es simple, pero no es una manera estructurada de tenerlos, ni de acceder a ellos ordenadamente lo que se consigue a través de bases de datos.
Bases de datos en R
Si los datos tabulados son la base de tu investigación en R, quizás sería conveniente no usar ficheros locales (.RData, .csv) y te interese organizarlos en una base de datos donde estarán más ordenados y el acceso será eficiente y optimizado. Las bases de datos llevan ya unos cuantos años con nosotros y la programación de los drivers de acceso interno está altamente optimizada.
Una base de datos (típica tipo relacional) es un conjunto de tablas con columnas-variables y filas-registros. Estas tablas pueden estar relacionadas unas con otras mediante enlaces (joins) siempre que tengan algún campo común que las ligue.
Para consultar una base de datos relacional se usa el lenguaje SQL (Structured Query Language) que es un estándar aceptado por todos los sistemas. Existen varios tipos de bases de datos, pero para entornos de programación habituales las más usadas son las bases de datos relacionales, que son las típicas formadas por tablas de variables y registros.
Nota: Actualmente se usa mucha información tipo no relacional o NoSQL en bases de datos formadas por estructuras flexibles no tabuladas (por ejemplo formada por ficheros JSON). Este tipo de bases de datos es también accesible desde R, pero se escapa de esta breve introducción al tema.
Para acceder a una base de datos se han creado driver específicos que gestionan la parte compleja y permiten interactuar de manera sencilla con ellas. Este driver es específico para cada tipo de base de datos y básicamente dependen del creador de la misma y los principales son: los sistemas JDBC (de Oracle) o el ODBC (de Microsoft). Al final estos entornos actúan como APIs, gestionando la comunicación entre la base de datos y el lado del cliente y son estándares.
En R hay paquetes que permiten la conexión ODBC directamente, la JDBC tiene que pasar por Java, pero vamos a simplificar las cosas, nos olvidamos de ODBC y vamos directos a usar DBI (DataBase Interface). DBI fue una propuesta para dar acceso nativo a bases de datos desde R, tiene muchas ventajas, unos métodos claros y una forma de trabajo simple.
El paquete DBI proporciona la sintaxis adecuada para acceso a múltiples tipos de bases de datos (SQLite, MySQL, MariaDB, PostgreSQL, Oracle). Esta librería aporta funciones genéricas para interactuar con la la base de datos desde R permitiendo por ejemplo mandar consultas SQL.
Usar el paquete DBI es bastante simple, pero tiene una desventaja, y es que para usar la base de datos debemos saber cómo hacer consultas a la misma (debemos usar el lenguaje SQL). Aunque este lenguaje de consultas es sencillo, no resulta adecuado para entorno de programación, pues sus llamadas son en texto plano y se extienden bastante. Además para consultas complejas se puede complicar con mucho texto descriptivo. Por lo tanto, y aunque anotamos que podemos usar library(DBI) para muchas cosas, no va a ser el paquete que usemos en este ejemplo introductorio a las bases de datos en R, y apostamos por lo más simple y directo que es usar dplyr.
dplyr
Esta librería (dplyr) integra a la perfección el entorno R de tidyverse con las bases de datos (usa DBI de fondo) y da como resultado una forma natural de usar desde R accesos a bases de datos utilizando el mismo tipo de programación y coherencia de datos a la que estamos acostumbrados los erreros.
Además contiene conectores para la mayoría de los tipos habituales de bases de datos entre las que se encuentran SQLite, PostgreSQL, MySQL/MariaDB, Hadoop, Spark, Hive, Impala.
Para hacer este sencillo, pero completo ejemplo vamos a usar RSQLite, que es una extensión de las bases de datos SQLite sobre el motor de R. Todo lo necesario para esto lo tenemos en la librería RSQLite.
SQLite es motor de bases de datos más usado del mundo, es de código libre, dominio público y un motor rápido, pequeño, optimizado y autocontenido que incluye todos los estándares que pueden esperarse de bases de datos habituales.
Ejemplo práctico
Vamos con el caso práctico, que va de bolsa, un tema que ya sabeis que me gusta, y del que además podemos descargar muchos datos de internet.
En este caso vamos a usar las series diarias de un par de acciones de bolsa y las vamos a almacenar en una base de datos RSQLite todo desde R.
Lo primero es cargar las librerías que necesitamos y con la función dbConnect creamos directamente la base de datos en una ruta local que se almacenará como un fichero tipo .rsqlite. Si existiese ya el fichero, en lugar de crearse se conectaría a la misma, estableciendo una conexión que es el enlace que usaremos en cada llamada posterior.
RSQLite es autocontenido por lo que es una opción estupenda para almacenar los datos en el equivalente a un fichero, pero con la ventaja de ser base de datos.
# Librerías necesarias( aunque en el pc tienes que tener ODBC instalado)
library(RSQLite)
library(dplyr)
# CREARMOS BASE DE DATOS
# para ello establecemos la conexión inicial
con <- dbConnect(
SQLite(),
"datos_bolsa.sqlite", # ruta local de la bd
extended_types = TRUE # es necesario para que almacene tipos no integer
)
# para cerrar la conexion una vez finalizadas las consultas usaremos:
# dbDisconnect(con)Si es la primera vez que lo ejecutamos, la base de datos estará vacía, así que lo primero será descargar unos datos de prueba para llenar una primera tabla, para esto vamos a usar la librería tidyquant, que permite descargar datos de bolsa de yahoo a una tabla tipo tibble con la función tq_get().
# usaremos la libraría tidyquant para descargar datos de bolsa de internet
library(tidyquant)
# La función tq_get() descarga datos del ticker
# bajamos datos diarios de los valores de neflix y microsoft
aux<-tq_get(c("NFLX","MSFT"),get="stock.prices",from = " 2022-01-01")
aux<-na.omit(aux) # quitamos los NA si los hubiera
glimpse(aux) # vemos lo descargado que es un tibble## Rows: 556
## Columns: 8
## $ symbol <chr> "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX…
## $ date <date> 2022-01-03, 2022-01-04, 2022-01-05, 2022-01-06, 2022-01-07, …
## $ open <dbl> 605.61, 599.91, 592.00, 554.34, 549.46, 538.49, 536.99, 544.2…
## $ high <dbl> 609.99, 600.41, 592.84, 563.36, 553.43, 543.69, 543.91, 544.2…
## $ low <dbl> 590.56, 581.60, 566.88, 542.01, 538.22, 526.32, 530.07, 532.0…
## $ close <dbl> 597.37, 591.15, 567.52, 553.29, 541.06, 539.85, 540.84, 537.2…
## $ volume <dbl> 3067500, 4393100, 4148700, 5711800, 3382900, 4486100, 3077800…
## $ adjusted <dbl> 597.37, 591.15, 567.52, 553.29, 541.06, 539.85, 540.84, 537.2…Ya tenemos los datos en la variable aux, y para almacenarlo como tabla en la base de datos usaremos la función dbWriteTable():
# CREAMOS UNA TABLA EN LA BASE DE DATOS
dbWriteTable(con, # nombre de la conexión a la bd
"DAT_DIARIOS", # nombre de la tabla creada
value = aux, # valores que se meten en la tabla
overwrite = TRUE
)
# VER LAS TABLAS EXISTENTES EN LA BD
dbListTables(con)## [1] "DAT_DIARIOS"# VER LOS CAMPOS EXISTENTES EN UNA TABLA
dbListFields(con, "DAT_DIARIOS")## [1] "symbol" "date" "open" "high" "low" "close" "volume"
## [8] "adjusted"# PARA BORRAR UNA TABLA
# dbRemoveTable(con, "DAT_DIARIOS")Con este simple código hemos creado la base de datos, y una primera tabla llamada DAT_DIARIOS en la que se han almacenado varios campos con los datos diarios descargados de internet de dos valores de bolsa.
Si quisiéramos añadir nuevos datos a esta misma tabla, por ejemplo descargando otros datos diarios de otro valor lo haríamos con la función añadir dbAppendTable() así:
# Descargamos otra serie diaria de datos de bolsa de AAPL (apple)
aux<-tq_get(c("AAPL"),get="stock.prices",from = " 2022-01-01")
aux<-na.omit(aux) # quitamos los NA si los hubiera
glimpse(aux) # vemos lo descargado que es un tibble## Rows: 278
## Columns: 8
## $ symbol <chr> "AAPL", "AAPL", "AAPL", "AAPL", "AAPL", "AAPL", "AAPL", "AAPL…
## $ date <date> 2022-01-03, 2022-01-04, 2022-01-05, 2022-01-06, 2022-01-07, …
## $ open <dbl> 177.83, 182.63, 179.61, 172.70, 172.89, 169.08, 172.32, 176.1…
## $ high <dbl> 182.88, 182.94, 180.17, 175.30, 174.14, 172.50, 175.18, 177.1…
## $ low <dbl> 177.71, 179.12, 174.64, 171.64, 171.03, 168.17, 170.82, 174.8…
## $ close <dbl> 182.01, 179.70, 174.92, 172.00, 172.17, 172.19, 175.08, 175.5…
## $ volume <dbl> 104487900, 99310400, 94537600, 96904000, 86709100, 106765600,…
## $ adjusted <dbl> 180.9597, 178.6631, 173.9106, 171.0075, 171.1765, 171.1964, 1…# Esta vez en lugar de escribir la tabla usamos append para añadir datos a la misma
dbAppendTable(con, "DAT_DIARIOS", aux) ## [1] 278Si hubiésemos que añadir un registro sería mejor usar la función rows_insert() o rows_update() para actualizar datos de una selección concreta (ver esta web para ejemplos).
Acceso a la BD
Una vez creada y con datos, ¿cómo accedemos a ellos?. Pues hay que tener en cuenta una cosa, cuando hacemos una consulta DBI o con dplyr por defecto el resultado que nos muestra no es completo, nos da solo el encabezado o las primeras líneas de la consulta, por lo que si vamos a usar los datos consultados tenemos que o bien descargar la base de datos completa a memoria con la función collect(), o usar dbFetch() si usamos la libraría DBI.
# ACCESO A LA BD DESDE R
# para tener todos los datos en local usamos la función collect
db <- tbl(con, "DAT_DIARIOS") # Lee la bd como consulta,
# para usar de forma completa hay que descargar con collect
db <- db |> collect() # ahora si tenemos una copia exacta
glimpse(db) # vemos los datos## Rows: 834
## Columns: 8
## $ symbol <chr> "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX", "NFLX…
## $ date <date> 2022-01-03, 2022-01-04, 2022-01-05, 2022-01-06, 2022-01-07, …
## $ open <dbl> 605.61, 599.91, 592.00, 554.34, 549.46, 538.49, 536.99, 544.2…
## $ high <dbl> 609.99, 600.41, 592.84, 563.36, 553.43, 543.69, 543.91, 544.2…
## $ low <dbl> 590.56, 581.60, 566.88, 542.01, 538.22, 526.32, 530.07, 532.0…
## $ close <dbl> 597.37, 591.15, 567.52, 553.29, 541.06, 539.85, 540.84, 537.2…
## $ volume <dbl> 3067500, 4393100, 4148700, 5711800, 3382900, 4486100, 3077800…
## $ adjusted <dbl> 597.37, 591.15, 567.52, 553.29, 541.06, 539.85, 540.84, 537.2… # comprobamos que tenemos los datos de los 3 valores descargados
unique(db$symbol)## [1] "NFLX" "MSFT" "AAPL"Como veis, en 4 líneas hemos creado una base de datos completa que nos permite un acceso ordenado. Para compartir los datos bastaría con pasar el fichero datos_bolsa.rsqlite y crear desde R una nueva conexión a los mismos.
Además al usar dplyr las consultas a la base de datos se simplifican mucho y no es necesario saber SQL al hacer dplyr de traductor interlingua.
Vamos a ver algunos ejemplos de consultas con dplyr sobre nuestra base de datos. en primer lugar vamos a realizar una gráfica de los valores descargados.
# para pintar un gráfico
library(ggplot2)
# HACEMOS CONSULTA Y PINTAMOS GRÁFICA
db %>% filter(date > "2022-01-01") %>% group_by(symbol) %>% collect() %>% ggplot(aes(x = date, group = symbol)) + geom_candlestick(aes(open = open, high = high, low = low, close = close)) +
labs(title = "Gráficas diarias",
subtitle = "Fecha",
y = "Precio", x = "") +
facet_wrap(~ symbol, ncol=2, scale = "free_y") +
theme_tq() # plantilla tidyquant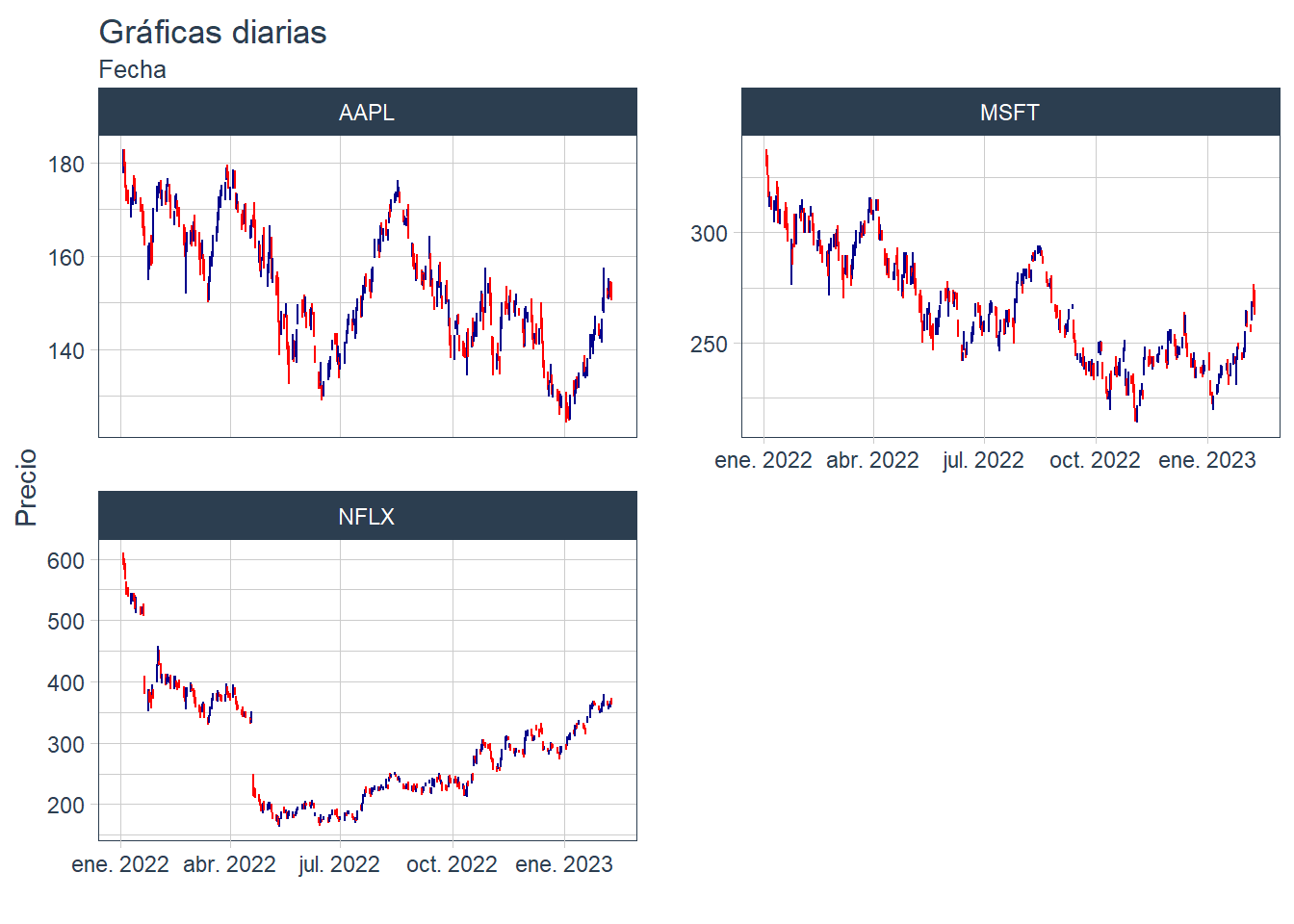
Consultas con dplyr
Para hacer consultas con dplyr usaremos el operador tubería (“pipe”) %>% que enlaza la salida de una consulta con la siguiente. Las principales funciones que podemos usar de consulta y subselección de dplyr son:
select()para seleccionar campos o variablesfilter()para seleccionar filas o registros ymutate()para crear campos nuevos calculados.group_by()agrupa los datos por cada valor de la variable/es indicadas
Aunque hay muchas más disponibles:
left_join(), permite enlazar tablas, la primera con la segunda nombrada siempre que tengan una columna común que sirve de enlace.rename()cambia de nombre una columnaarrange()ordena por la columna seleccionadatransmute()calcula una variable y se queda solo con esta nueva borrando el restosummarise()calcula medias o cualquier función sobre una variablestarts_with(),ends_with(),contains(),matches()operadores para consulta que indica que el nombre empieza con, termina, contiene, coincide con. estos operadores están en la libraríalibrary(tidyselect).
Tidyverse funciona con tibbles en lugar de data.frames, la verdad que apenas notarás las diferencias, pero tienen algunas mejoras como en la presentación por defecto en pantalla. Si partimos de data.frame podemos hacer una conversión rápida con la función as_tibble() y la opuesta con as.data.frame().
Veamos algunos ejemplos de uso de nuestra nueva base de datos de valores diarios:
# Seleccionar los valores de fecha y cierre de MICROSOFT desde enero 23
consulta1<- db %>% select(date,symbol,close) %>% filter(date > "2023-01-01" & symbol=="MSFT" )
glimpse(consulta1)## Rows: 27
## Columns: 3
## $ date <date> 2023-01-03, 2023-01-04, 2023-01-05, 2023-01-06, 2023-01-09, 20…
## $ symbol <chr> "MSFT", "MSFT", "MSFT", "MSFT", "MSFT", "MSFT", "MSFT", "MSFT",…
## $ close <dbl> 239.58, 229.10, 222.31, 224.93, 227.12, 228.85, 235.77, 238.51,…#Selecciona los ultimos valores de la bd
db %>% last(3)## # A tibble: 3 × 8
## symbol date open high low close volume adjusted
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 AAPL 2023-02-07 151. 155. 151. 155. 83322600 155.
## 2 AAPL 2023-02-08 154. 155. 151. 152. 64120100 152.
## 3 AAPL 2023-02-09 154. 154. 150. 151. 56007100 151.# Cuenta cuantos datos diarios por valor
db %>% select(date,symbol,adjusted) %>%
group_by(symbol) %>% tally() ## # A tibble: 3 × 2
## symbol n
## <chr> <int>
## 1 AAPL 278
## 2 MSFT 278
## 3 NFLX 278# qué valores hay
db %>% distinct(symbol)## # A tibble: 3 × 1
## symbol
## <chr>
## 1 NFLX
## 2 MSFT
## 3 AAPL# Consulta de calculos resumen
db %>% select(symbol,adjusted) %>% group_by(symbol) %>% summarise(
min= min(adjusted),
max= max(adjusted),
var= sd(adjusted)
)## # A tibble: 3 × 4
## symbol min max var
## <chr> <dbl> <dbl> <dbl>
## 1 AAPL 125. 181. 13.2
## 2 MSFT 214. 332. 25.1
## 3 NFLX 166. 597. 91.7# selecciona los valores de octubre 22 DE microsoft
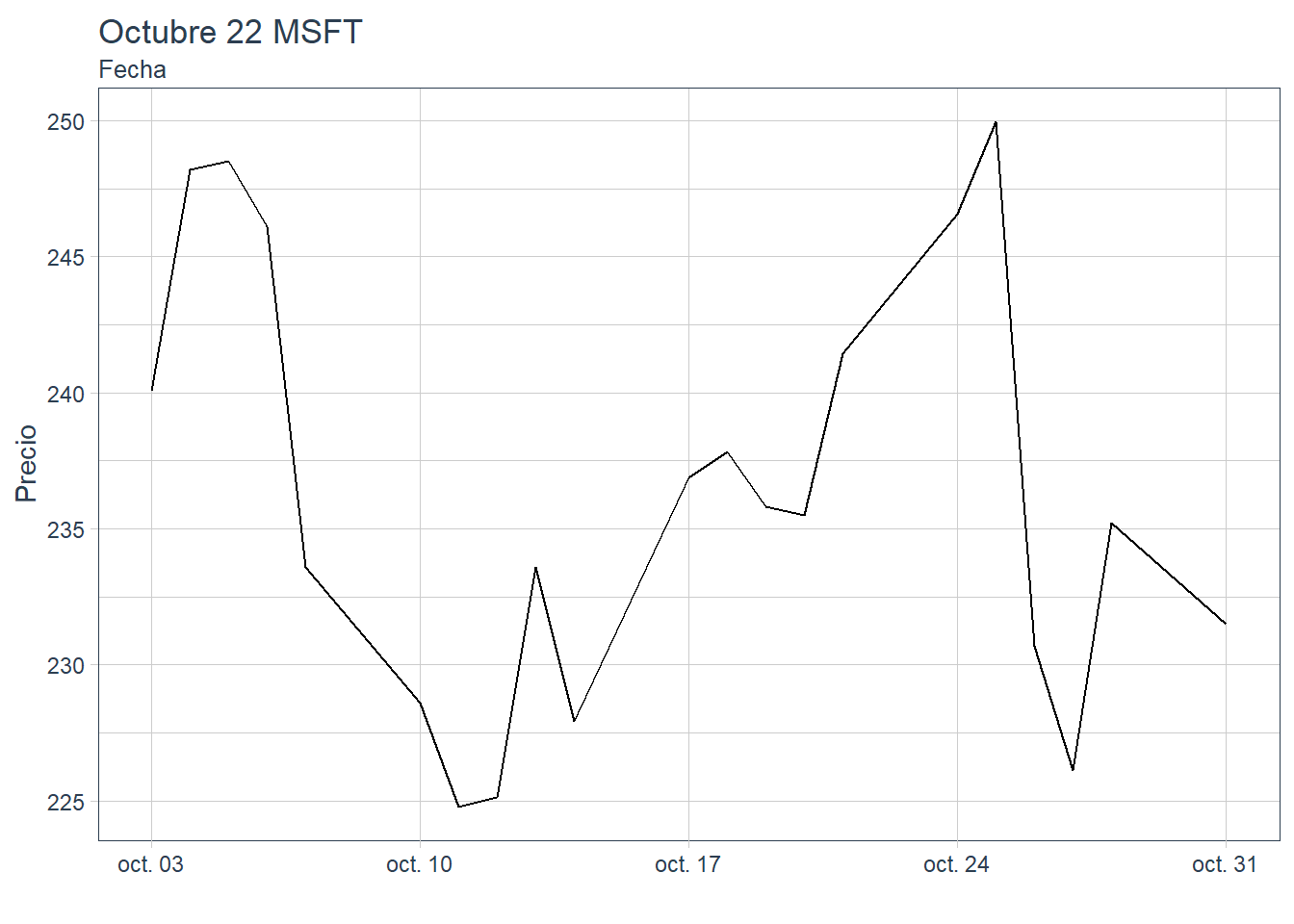
consulta2 <- db %>% select(date,symbol,adjusted) %>% filter(between(date,as.Date("2022-10-01"),as.Date("2022-10-31")) & symbol == "MSFT")
# HACEMOS CONSULTA Y PINTAMOS GRÁFICA
consulta2 %>% ggplot(aes(x = date, group = symbol)) + geom_line(aes(y=adjusted)) +
labs(title = "Octubre 22 MSFT",
subtitle = "Fecha",
y = "Precio", x = "") +
theme_tq() # plantilla tidyquant