
Exploratory Data Analisys con R
Exploratory Data Analisys con R
Llamamos Análisis Exploratorio de Datos (acrónimo EDA del inglés) al proceso inicial de reconocimiento o, lo que sencillamente entendemos como echar un vistazo a los datos y así empezar a comprender un poco lo que contienen y qué se puede hacer con ellos.
He dividido el artículo en 3 partes, en la primera vemos “lo básico” e imprescindible que son las funciones de RBase para echar un vistazo a los datos tabulados. En la segunda parte hablamos de las librerías especícifas para EDA que aportan gran valor al simplificar procesos, gráficas y en general facilitar el primer contacto con datos tabulados para su mejor comprensión. En concreto veremos los paquetes skimr, visdat y el que más me gusta inspecdf.
En la 3º parte os indico, sin entrar en mucho detalle, algunos paquetes que hacen EDA de forma automatizada generando completos informes con un click.
Introducción. Trabajar con tablas
Una tabla es un conjunto estructurado de datos ordenados en filas (registros) y columnas (variables).
Antes de empezar a usar una tabla en nuestros análisis, lo primero que debemos comprobar es que se trata de datos procesados, es decir, que cumplen estas 5 reglas:
- cada variable debe estar en una sola columna
- cada observación debe estar en una fila diferente
- debe haber una tabla para cada tipo de variables
- cada variable o columna debe tener un nombre y este debe tener sentido.
- cada tabla debe estar en un fichero diferente.
Lo habitual, es que NO LOS CUMPLA, y tengamos que trabajar sobre los datos brutos hasta obtener una tabla de datos procesados. En este post veremos, como ejemplo, las funciones para pasar de tabla larga a tabla ancha para cumplir estas reglas.
Obtención de datos
Para ver un caso real de verdad y no la típica tabla de ejemplo de una librería os propongo buscar datos en alguna de estas webs:
- kaggle es una web que ofrece open data
- 10-datasets-kids
- La EU ofrece datos y tablas en abierto “oficiales” https://data.europa.eu/es
- Datos económicos delbanco muncial
- google researche
- Gobierno de España
Descarga de datos de trabajo
Para nuestro ejemplo vamos a usar datos de compra-venta de viviendas en España que he encontrado en la web de datos abiertos del Gobierno de España aquí.
Podemos descargar el fichero directamente de la web con formato csv o copiar el enlace a R y bajarlo con código como explico en el bloque siguiente. Usamos la función read.csv() para leer el fichero descargado.
# descarga de datos directamente con R
library(RCurl)
viv<-getURL("https://www.ine.es/jaxiT3/files/t/es/csv_bdsc/3240.csv")# Lectura de la tabla csv a R
viv_df<-read.csv(viv,header = T,sep = ";",strip.white = TRUE,stringsAsFactors = F, encoding="UTF-8")En realidad, te confieso que para leer esta tabla correctamente he tenido que descargar antes los datos y ver algunas cosas internas del fichero, como ver si tiene encabezado de las columnas (header = T), ver qué separador de campos usa (sep = ";"). También he incluido el encoding="UTF-8" que hace que la lectura de tildes y eñes del español se lean bien y no se corrompa con extraños símbolos.
Como ves, obtener los datos requiere de un proceso de prueba y error 💪 . Por eso me gusta empezar con casos reales y no con data.frame de prueba que traen los paquetes, que ya tienen todo masticadito y perfecto.
Parte 1. Primer vistazo -EDA
Ahora que tenemos la tabla bruta lo primero es echar un vistazo a los datos y para eso lo mejor es usar las funciones de RBase clásicas que son:
str()➡️ muestra un resumen de la estructura de la tablahead()ytail()➡️ muestra los primeros o últimos registrossummary()➡️ hace un resumen estadistico por variablesglimpse()de dplyr lo mismo que str, pero más compacto.dim()➡️ da las dimensiones de la tablanrow(),ncol()➡️ el número de filas o de columnas que tiene.table(df$col1)➡️ resúmenes agregados por columan (cuenta casosunique()➡️ nos muestra los valores únicos (sin repeticiones) de una variableaggregate()➡️ una función super util para resumir y agregar datos de manera simple.View(df)te muestra la tabla con las celdas directamente en RSTUDIO.
Veamos algún ejemplo:
# Primer vistazo a los datos con RBase
#str(viv_df) # = que glimpse()
head(viv_df,3)## X.U.FEFF.Naturaleza.de.la.finca Provincias Duración.en.años
## 1 Fincas de secano Total Nacional Total
## 2 Fincas de secano Total Nacional Total
## 3 Fincas de secano Total Nacional Total
## Número.e.importe Periodo Total
## 1 Número de hipotecas 2003 20.616
## 2 Número de hipotecas 2002 19.909
## 3 Número de hipotecas 2001 18.664#tail(viv_df,3)
#summary(viv_df)
dplyr::glimpse(viv_df)## Rows: 47,700
## Columns: 6
## $ X.U.FEFF.Naturaleza.de.la.finca <chr> "Fincas de secano", "Fincas de secano"~
## $ Provincias <chr> "Total Nacional", "Total Nacional", "T~
## $ Duración.en.años <chr> "Total", "Total", "Total", "Total", "T~
## $ Número.e.importe <chr> "Número de hipotecas", "Número de hipo~
## $ Periodo <int> 2003, 2002, 2001, 2000, 1999, 1998, 19~
## $ Total <chr> "20.616", "19.909", "18.664", "19.361"~Con estas funciones verás que se trata de una tabla de 6 columnas y 47.700 filas. El primer problema es que los nombres de las columnas son muy largos, y esto no va bien para los futuros gráficos, así que vamos a renombrar las variables. esto se hace de una manera simple pasando un vector con los nombres nuevos ordenados:
# Nuevos nombres de las columnas
names(viv_df)<-c( "t_finca", "provincia", "años","importe","periodo","total")A mi me gusta ver una muestra aleatoria de datos y uso este pequeño truco
# Mostrar 6 registros aleatorios
viv_df[sample(1:nrow(viv_df),6),]## t_finca provincia años
## 25787 Solares 44 Teruel No consta
## 46617 Total bienes muebles 41 Sevilla Total
## 35088 Total fincas urbanas 30 Murcia No consta
## 33138 Total fincas urbanas 11 Cádiz Hasta 9 años
## 5430 Fincas de regadío 02 Albacete Hasta 9 años
## 39845 Total fincas rústicas y urbanas 24 León De 10 a 15 años
## importe periodo total
## 25787 Número de hipotecas 1997
## 46617 Importe de hipotecas 1997 1.899
## 35088 Número de hipotecas 1996 83
## 33138 Importe de hipotecas 1996 51.369
## 5430 Número de hipotecas 1994 13
## 39845 Número de hipotecas 1999 3.617De tabla larga a tabla ancha
En el resumen summary() de los datos he visto algo raro…. si os fijais, la columna “importe” tiene solo dos posibles valores Número de hipotecas, Importe de hipotecas y tiene pinta de que a cada valor de importe le corresponde un valor de la columna total. Esto no cumple los principios de datos procesados.
Han incluido dos variables en una misma columna. Es un típico caso de tabla larga, que hay que pasar a tabla ancha. Cada uno de los dos valores únicos de la columna “importe” están relacionados con la columna “total”, así que vamos a desdoblar esta columna en dos usando la librería tidyrincluida en tidyverse con la función pivot_wider() en la que decimos la columna que contiene los nombres y la columna que tiene los datos y la desdobla así creando 2 nuevas columnas.
library(tidyverse)# tidyr
# vamos a coger los datos de nombre de la col importe y los valores de total
viv_ancha <- pivot_wider(viv_df, names_from = importe, values_from = total)
# cambiamos los nombres de las dos columnas nuevas
names(viv_ancha)[5]<-"num_hipo"
names(viv_ancha)[6]<-"import_hipo"
# Vemos algunos registros aleatorios de esta nueva tabla
viv_ancha[sample(1:nrow(viv_ancha),6),]## # A tibble: 6 x 6
## t_finca provincia años periodo num_hipo import_hipo
## <chr> <chr> <chr> <int> <chr> <chr>
## 1 Otros 21 Huelva Hast~ 2003 "283" "41.055"
## 2 Fincas de secano 18 Granada De 1~ 2000 "566" "40.166"
## 3 Otros 33 Asturias De 1~ 2003 "826" "112.502"
## 4 Total bienes muebles 38 Santa Cruz de Tene~ Total 2000 "" ""
## 5 Fincas de secano 16 Cuenca De 1~ 2001 "140" "6.130"
## 6 Otros 15 Coruña, A De 1~ 2002 "735" "84.966"El proceso inverso se haría con la función pivot_longer().
Convertir a números los factores
Hay varias columnas numéricas que como vemos en el resumen las toma como factores o texto según hayamos usado stringsAsFactors = T en la lectura de los datos. El problema es que las variables numéricas no las ha interpretado como tal, quizás por el punto de los miles,así que vamos a quitarlo y transformar a numéricas.
Para hacer esto usaremos la función gsub(patron_a_cambiar,texto_remplazo,vector).
# convertimos las columnas de texto a numéricas y antes eliminamos el punto de miles
viv_ancha$import_hipo<-as.numeric(gsub("[.]", "",viv_ancha$import_hipo))
viv_ancha$num_hipo<-as.numeric(gsub("[.]", "",viv_ancha$num_hipo))
# Vemos algunos registros aleatorios
viv_ancha[sample(1:nrow(viv_ancha),6),]## # A tibble: 6 x 6
## t_finca provincia años periodo num_hipo import_hipo
## <chr> <chr> <chr> <int> <dbl> <dbl>
## 1 Total fincas rústicas 43 Tarrago~ Hast~ 1994 75 8721
## 2 Otros 52 Melilla Total 1999 8 535
## 3 Total bienes muebles 44 Teruel No c~ 1997 NA NA
## 4 Viviendas 11 Cádiz Mayo~ 1996 4315 177040
## 5 Viviendas 38 Santa C~ Total 1999 11614 635678
## 6 Total fincas rústicas y urbanas 20 Gipuzkoa No c~ 1998 221 23752Valores inválidos
Ahora nos surge otro problema, y es que vemos que los datos tiene muchos valores inválidos o NA. Los valores inválidos hay que contarlos siempre, para estimar la calidad de la muestra y quitarlos o imputarlos (rellenar con formulación en caso de que lo creamos necesario). En nuestro ejemplo fundamentalmente los quitaremos para las gráficas, pero hay que ver cuantos hay con las funciones siguientes.
sum(is.na(viv_ancha)) # cuenta los NAs totales## [1] 7930sum(complete.cases(viv_ancha)) # cuenta los casos completos de la tabla## [1] 19882nrow(na.omit(viv_ancha))# omite los casos inválidos y cuenta los que hay## [1] 19882#guardamos una nueva tabla solo con casos completos
viv_ancha2<-na.omit(viv_ancha)aggregate
Solo nos queda añadir al resumen de funciones un ejemplo de aggregate que para mi es una de las funciones más útiles en esta fase de ver los datos, pues nos permite hacer subtotales fácilmente.
# calculamos el num de hipotecas por año, descontando el total nacional
aggregate(num_hipo ~ periodo,viv_ancha[!viv_ancha$provincia == "Total Nacional",],sum)## periodo num_hipo
## 1 1994 3054724
## 2 1995 2888260
## 3 1996 2941378
## 4 1997 3417252
## 5 1998 3797014
## 6 1999 4196080
## 7 2000 4452730
## 8 2001 4479478
## 9 2002 5021326
## 10 2003 5566308Parte 2. Librerías para EDA básico
Hemos visto las funciones básicas de R para echar un vistazo inicial a los datos, a estas funciones les podemos añadir todas las funciones gráficas que queramos, con las que poder pintar las variables y sus relaciones (como hist(), plot(), o librerías como ggplot()), pero en lugar de hacerlo así, dedicaremos esta 2º parte a ver paquetes específicos para EDA y que directamente nos dan unas buenas funciones gráficas y tablas resumen en pocas líneas de código.
skimr
skimr es una librería que da un primer vistazo bueno y rápido al generar una mini-gráfica de histograma, así como un resumen completo por variables, pensado especialmente para verlo en pantalla y no para generar informes finales.
library(skimr)
skim(viv_ancha) # función principal| Name | viv_ancha |
| Number of rows | 23850 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| t_finca | 0 | 1 | 5 | 31 | 0 | 9 | 0 |
| provincia | 0 | 1 | 7 | 25 | 0 | 53 | 0 |
| años | 0 | 1 | 5 | 16 | 0 | 5 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| periodo | 0 | 1.00 | 1998.50 | 2.87 | 1994 | 1996.0 | 1998.5 | 2001.00 | 2003 | ▇▇▇▇▇ |
| num_hipo | 3962 | 0.83 | 4003.88 | 31203.57 | 1 | 28.0 | 170.0 | 1103.25 | 927629 | ▇▁▁▁▁ |
| import_hipo | 3968 | 0.83 | 298009.94 | 2496672.87 | 2 | 2002.5 | 14202.0 | 87294.75 | 99932769 | ▇▁▁▁▁ |
Se puede extraer cada una de las partes de este resumen:
#resumen de valores numéricos
viv_ancha %>%
skim() %>%
yank("numeric")Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| periodo | 0 | 1.00 | 1998.50 | 2.87 | 1994 | 1996.0 | 1998.5 | 2001.00 | 2003 | ▇▇▇▇▇ |
| num_hipo | 3962 | 0.83 | 4003.88 | 31203.57 | 1 | 28.0 | 170.0 | 1103.25 | 927629 | ▇▁▁▁▁ |
| import_hipo | 3968 | 0.83 | 298009.94 | 2496672.87 | 2 | 2002.5 | 14202.0 | 87294.75 | 99932769 | ▇▁▁▁▁ |
visdat
Otro paquete para ver los datos es visdat. Esta librería tiene una gráfica que me gusta bastante como resumen, con la función vis_dat(), que muestra la distribución por tipo de dato, e incluso los NA:
library(visdat)
#vis_miss(viv_ancha)
vis_dat(viv_ancha)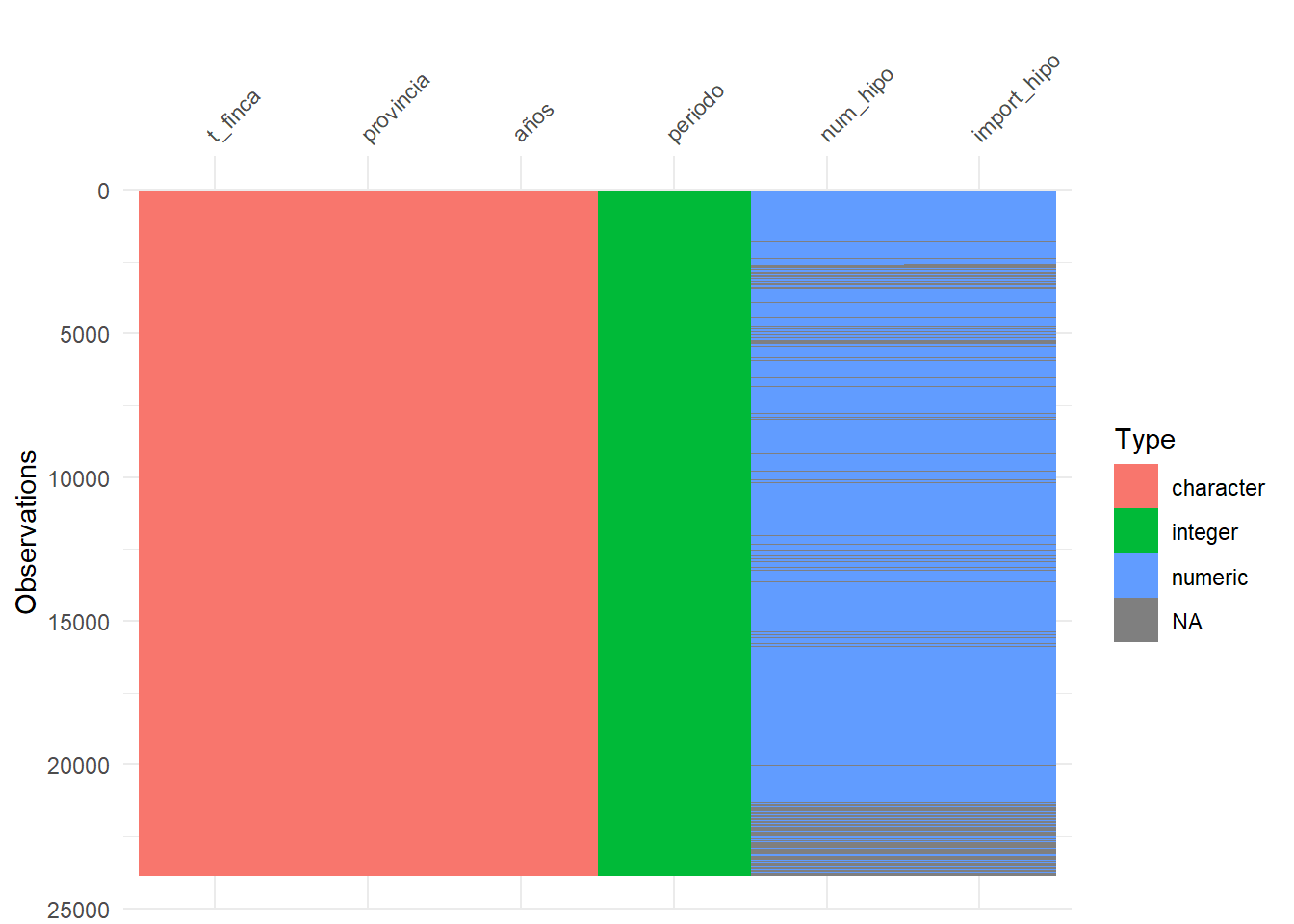
inspectdf
Como tercera opción y la que más me gusta está la librería inspectdf que proporciona gráficos resumen de gran calidad y concreción. La salida gráfica para las variables factores está muy conseguida y en general son intuitivos y de fácil comprensión.
Podeis encontrar más información en este fantástico post de littlemissdata. Veamos varias gráficas obtenidas con esta librería aplicada directamente a algunas de las tablas que hemos procesado en el ejemplo.
#devtools::install_github("alastairrushworth/inspectdf")
library(inspectdf)
# Graficas EDA con inspectdf sobre los datos de ejemplo
inspect_types(viv_ancha) %>% show_plot() # tipos de datos
inspect_mem(viv_ancha) %>% show_plot() # basic sizing information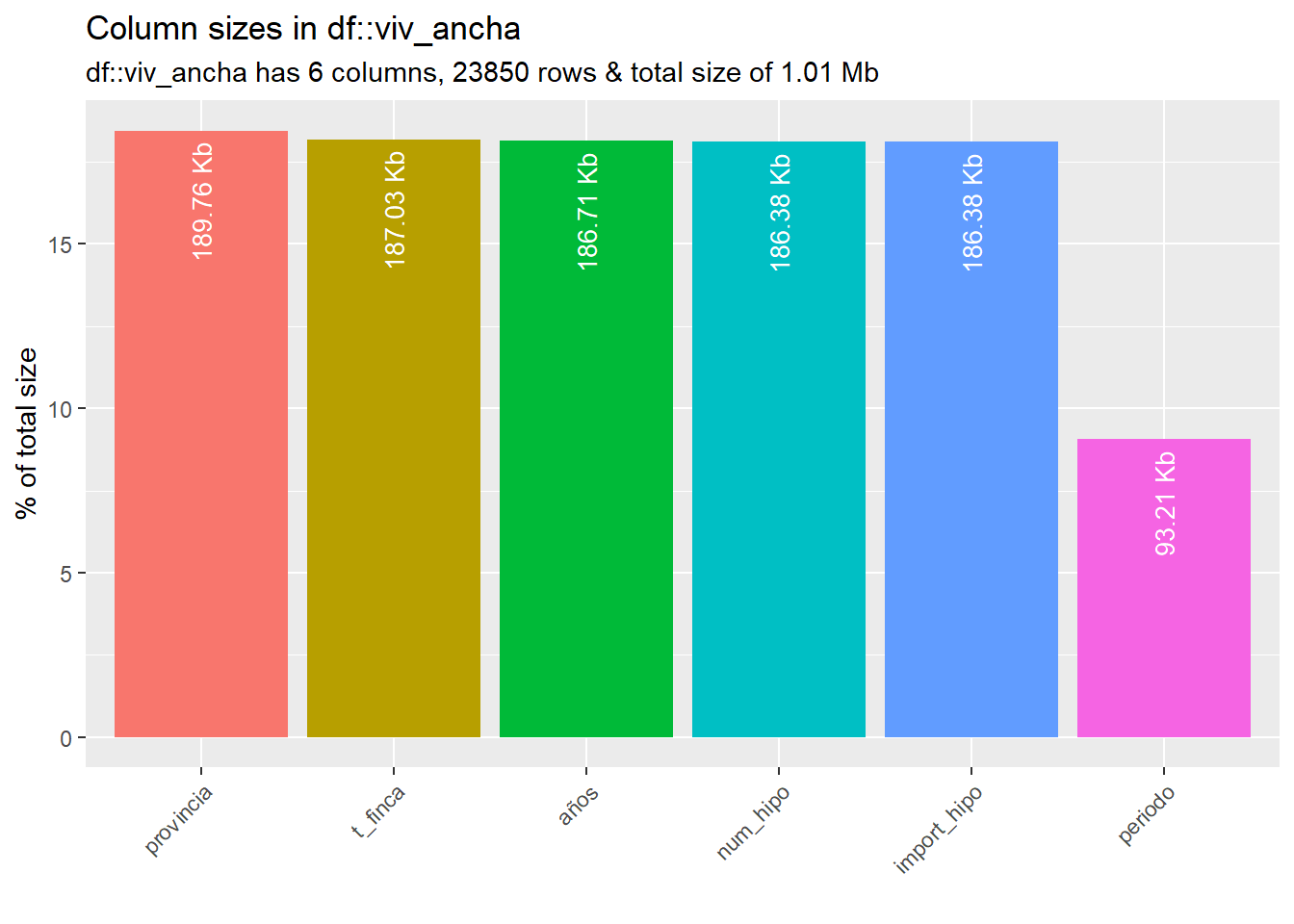
inspect_na(viv_ancha) %>% show_plot() # no va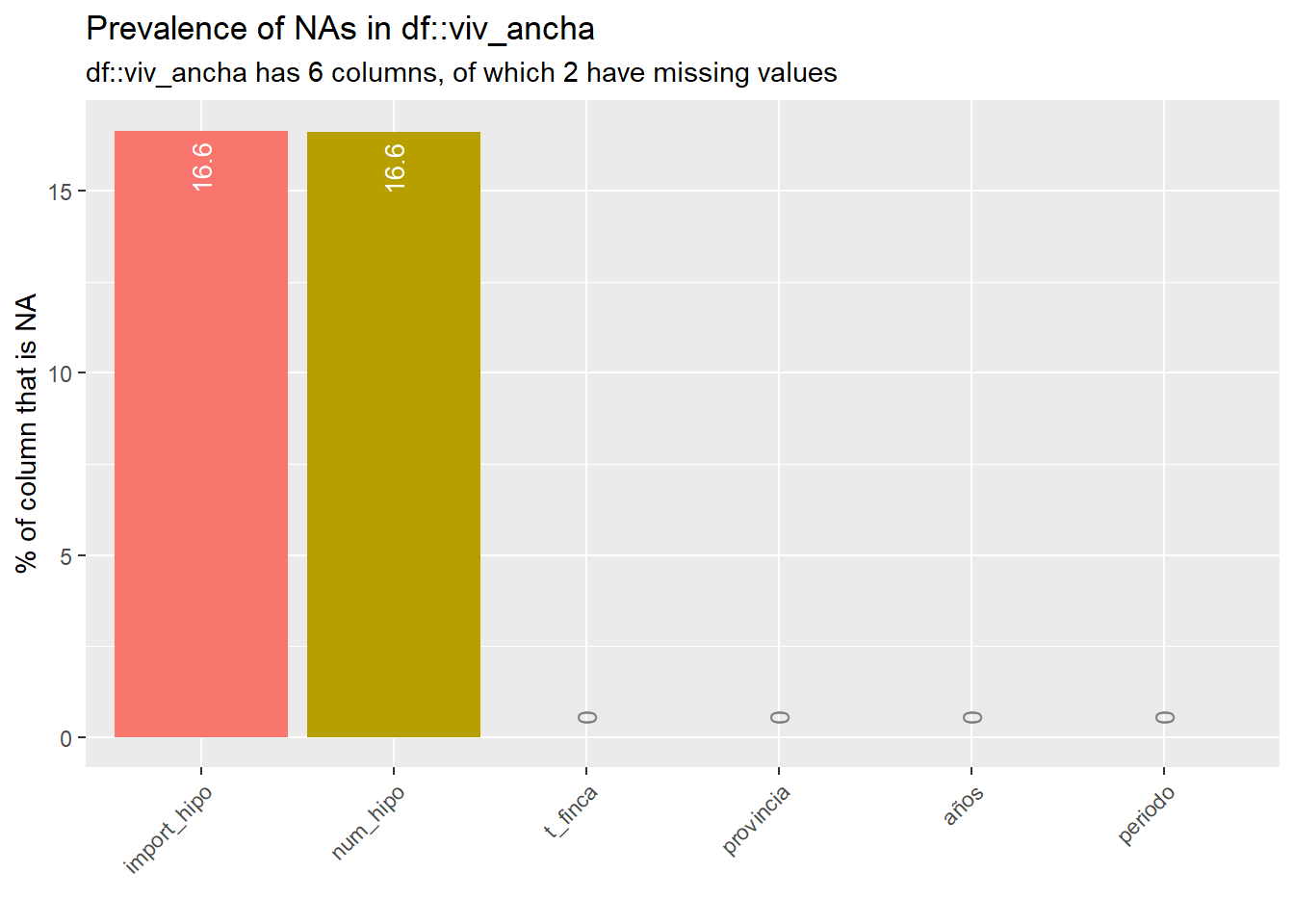
inspect_cat(viv_ancha) %>% show_plot() # ver categóricos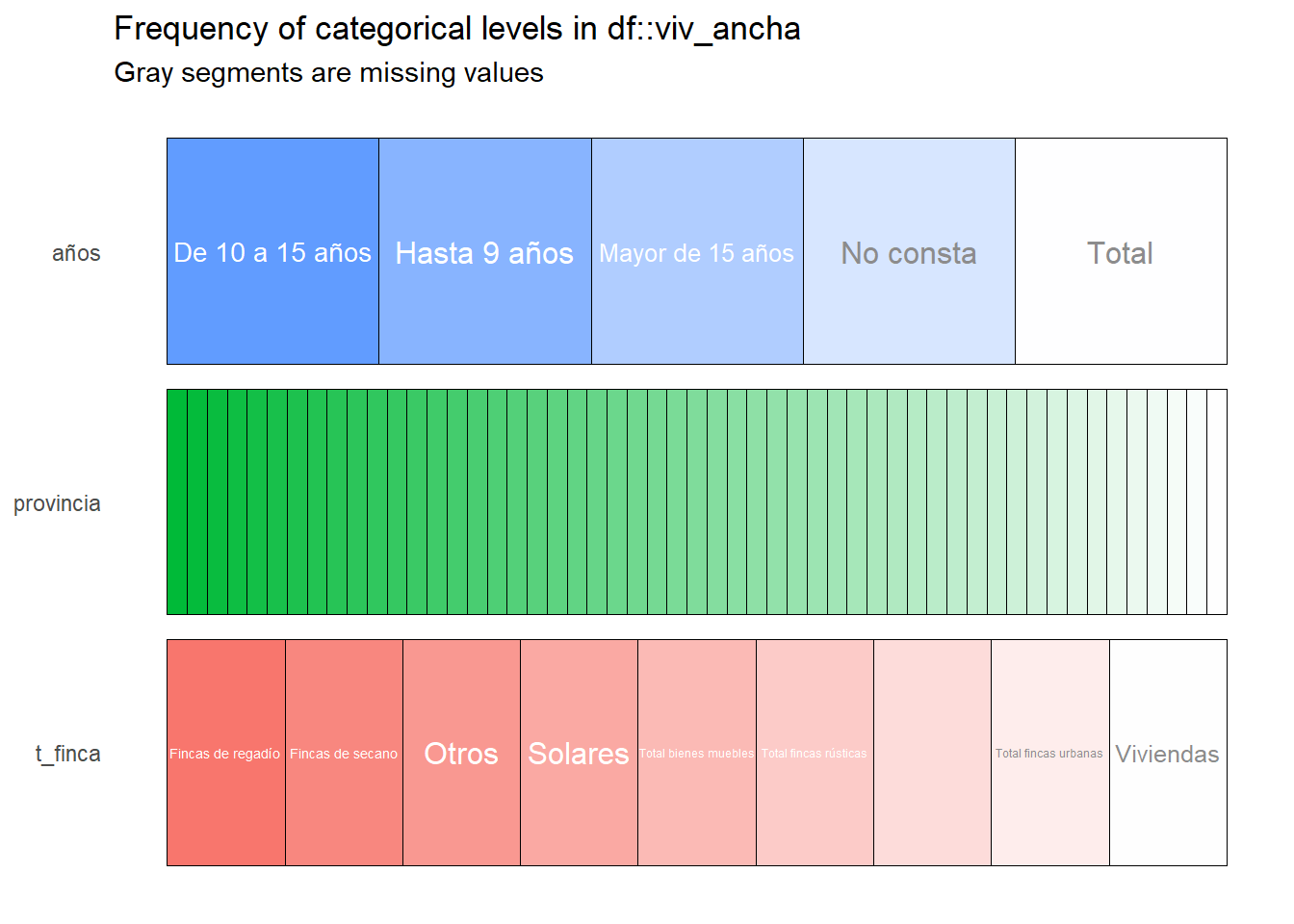 La gráfica que proporciona dividiendo por categorías es de lo mejor que he visto, muy visual y que permite un primer vistazo potente.
La gráfica que proporciona dividiendo por categorías es de lo mejor que he visto, muy visual y que permite un primer vistazo potente.
Las que resumen los datos numéricos también, pero en la tabla de muestra no se aprecia, así que vamos a pintar más ejemplos, pero usando la tabla airquality con datos de calidad del aire:
inspect_num(airquality) %>% show_plot() # explorar los numeric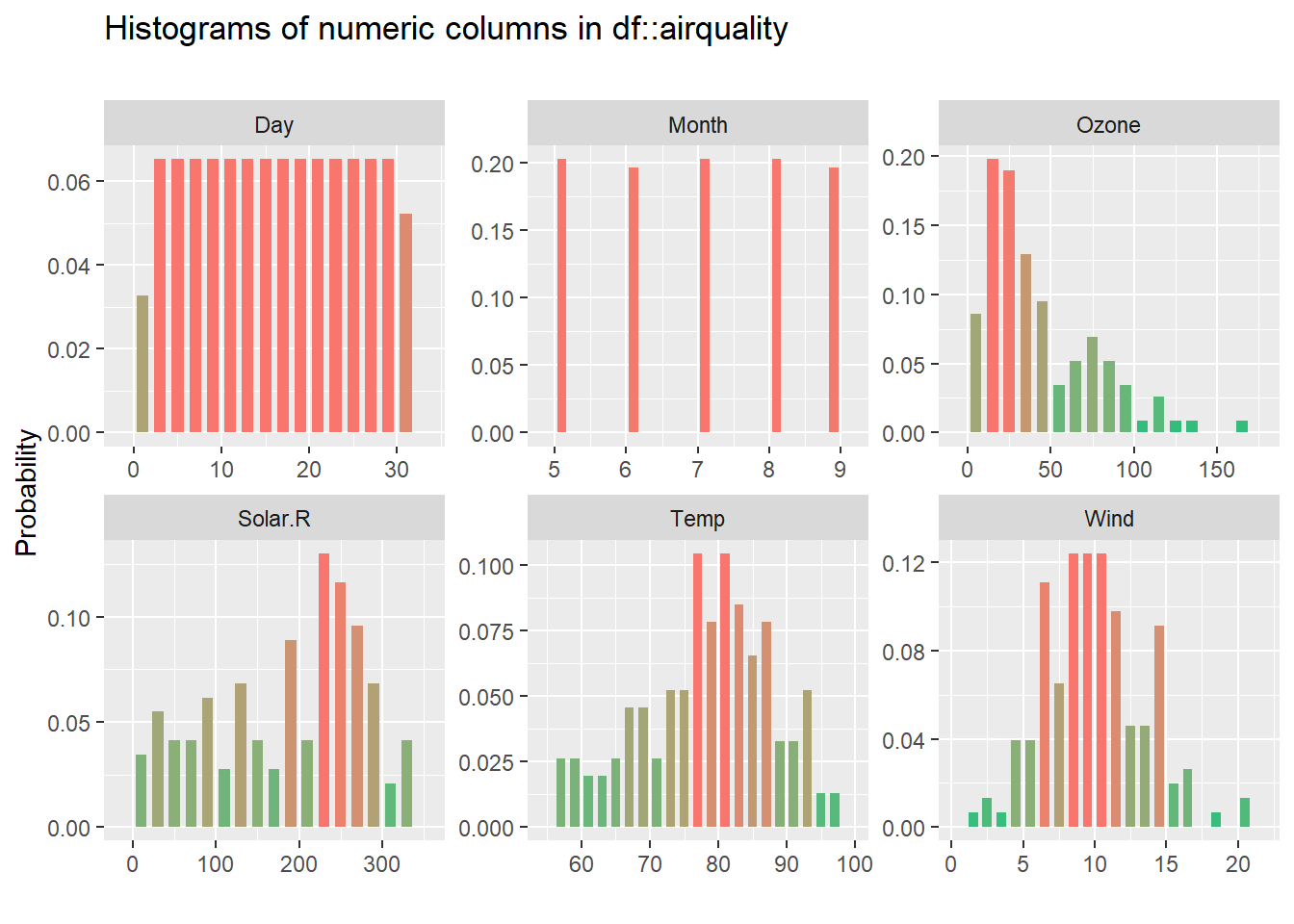
inspect_types(airquality) %>% show_plot()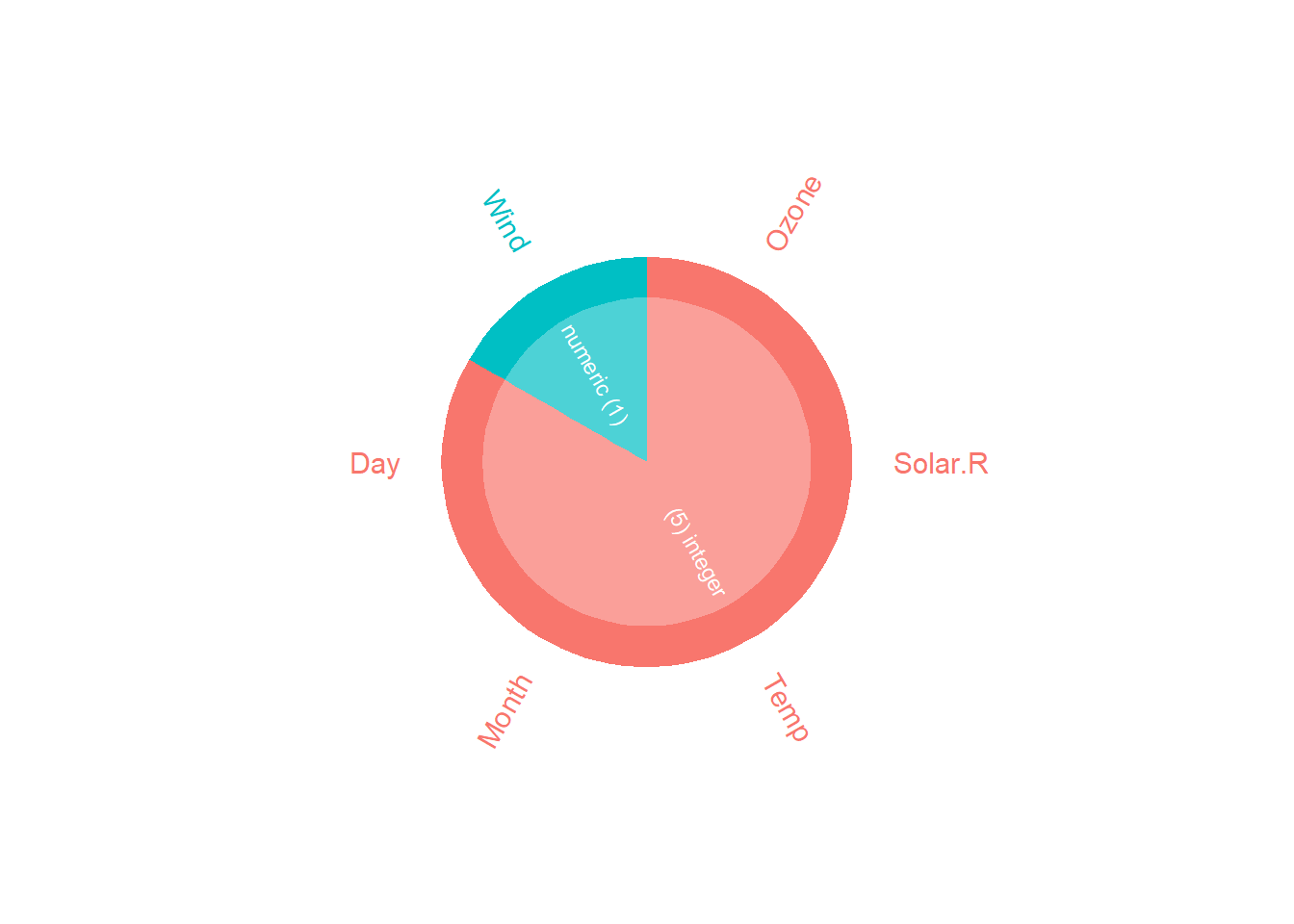
inspect_num(airquality) %>% show_plot()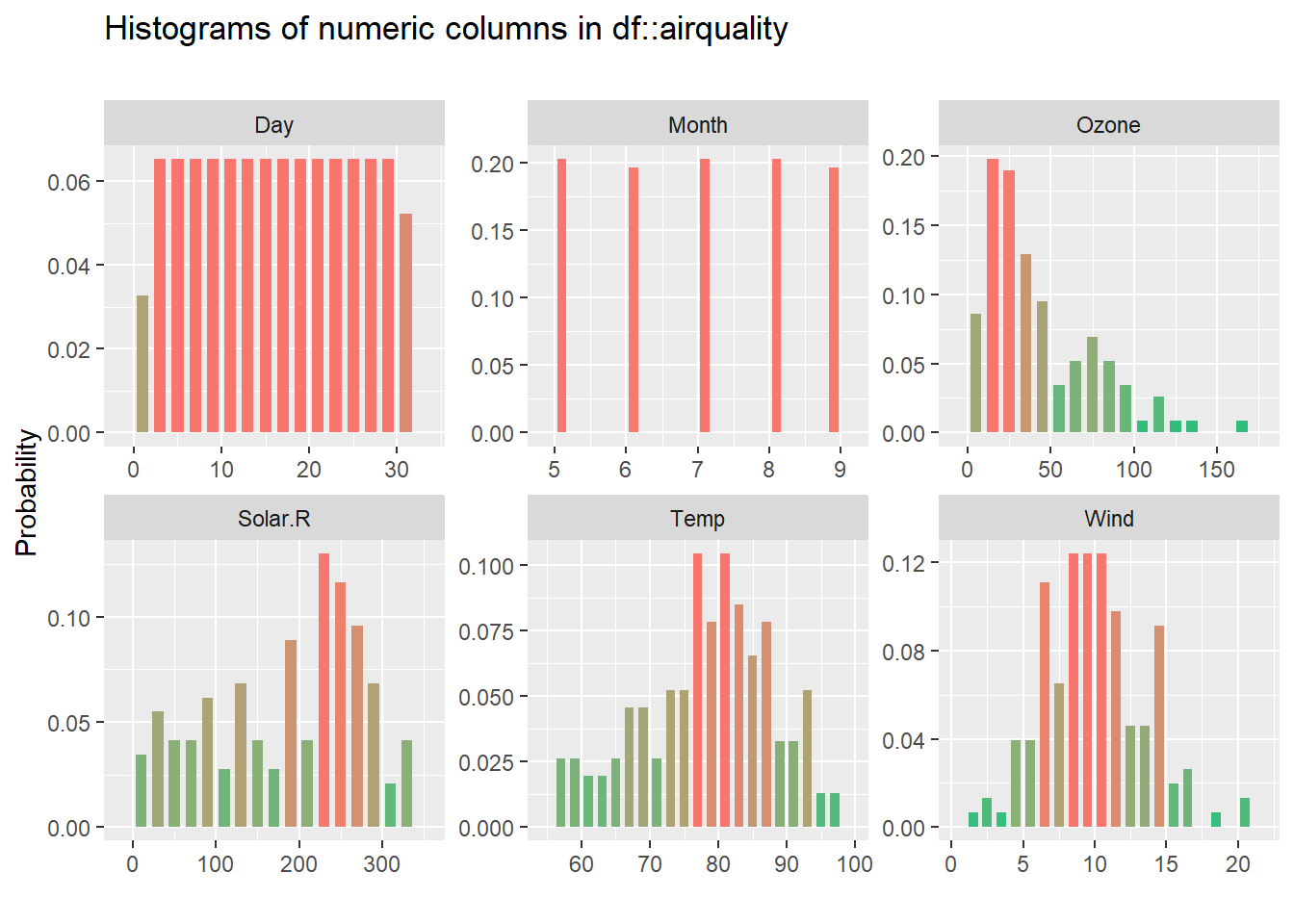
Una cosa interesante de inspectdf es que se puede comprar dos tablas similares, que tengan las mismas columnas y nos da gráficas muy interesantes. Por ejemplo, las tablas viv_ancha y viv_ancha2 se diferencian en que quitamos los NA o inválidos, veamos como lo representa:
# comparativa de dos tablas procesadas una sin NA
inspect_na(viv_ancha,viv_ancha2) %>% show_plot() # no va
inspect_cat(viv_ancha, viv_ancha2) %>% show_plot() # ver 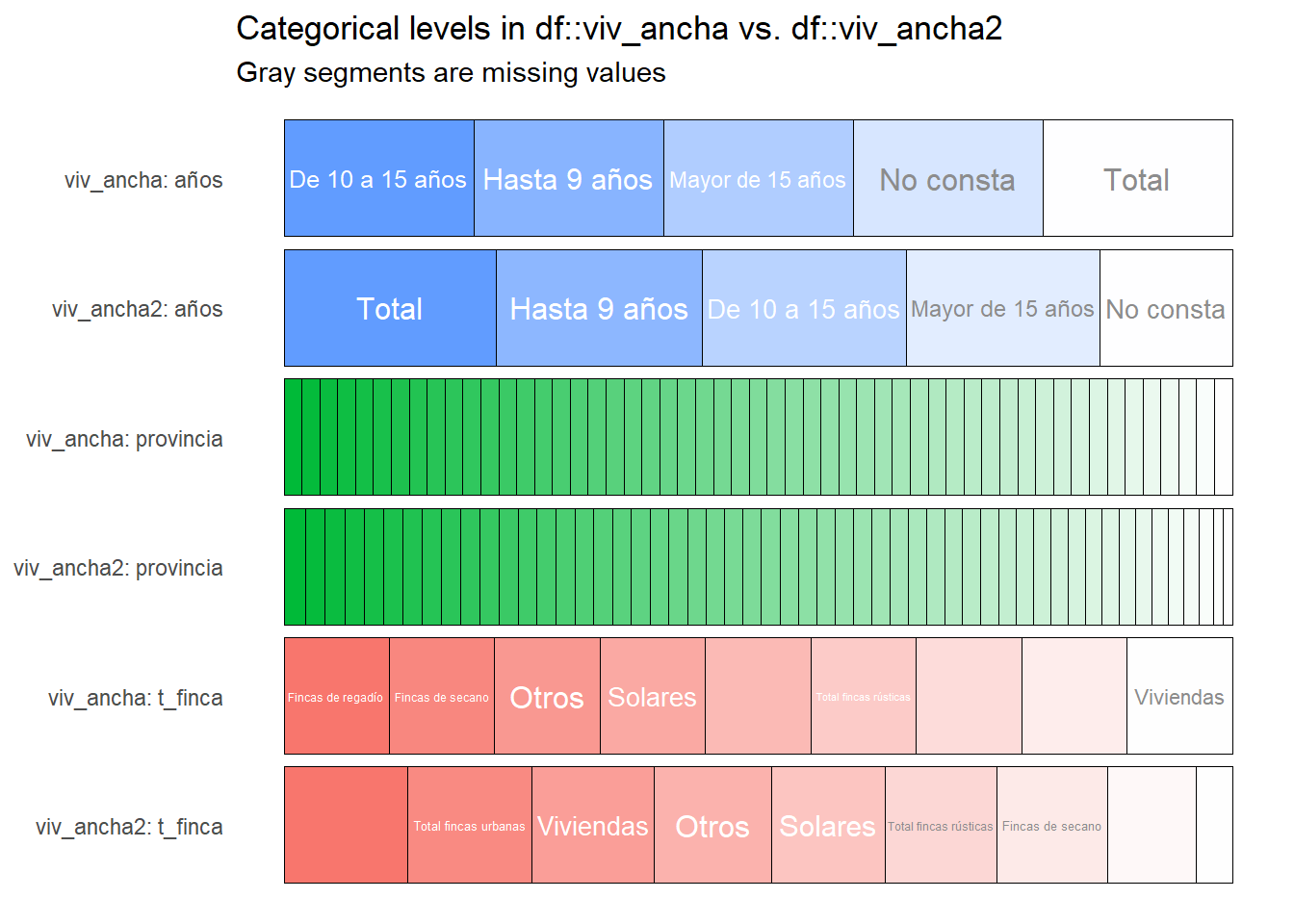
Parte 3. EDA automático
En esta tercera parte veremos paquetes que generan un informe completo y automático a partir de la tabla de datos, son la solución para tontos: pulse el botón rojo y listo 😜.
En realidad estas librerías son excelentes cuando tenemos unos datos de partida complejos con muchas columnas y registros, pues dan una salida resumen rápida y estructurada con excelentes gráficas, perfectas para copiar en informes.
DataExplorer
DataExplorer es la librería más conocida para análisis exploratorio EDA. Es muy simple y ofrece una salida -tipo informe- que aporta muchísima información. Su uso es tan fácil que asusta, solo cargamos la librería y llamamos la función create_report sobre la tabla que queremos ver.
library(DataExplorer)
# llamada a la función informe automático
create_report(viv_ancha)Lo que hace la función create_report es generar un documento en formato html llamado report.html que se guarda en el directorio de trabajo (si no sabes cual es usa getwd()). Si abrimos ese fichero veremos un completo análisis cuyo indice es el siguiente:

indice del informe DataExplorrer
Cada una de las gráficas y tablas del informe se puede hacer de forma independiente con funciones específicas de la librería, por ejemplo:
library(DataExplorer)
introduce(viv_ancha) #tabla resumen de columnas y tipos## # A tibble: 1 x 9
## rows columns discrete_columns continuous_columns all_missing_columns
## <int> <int> <int> <int> <int>
## 1 23850 6 3 3 0
## # ... with 4 more variables: total_missing_values <int>, complete_rows <int>,
## # total_observations <int>, memory_usage <dbl># gráfico intro
plot_intro(viv_ancha)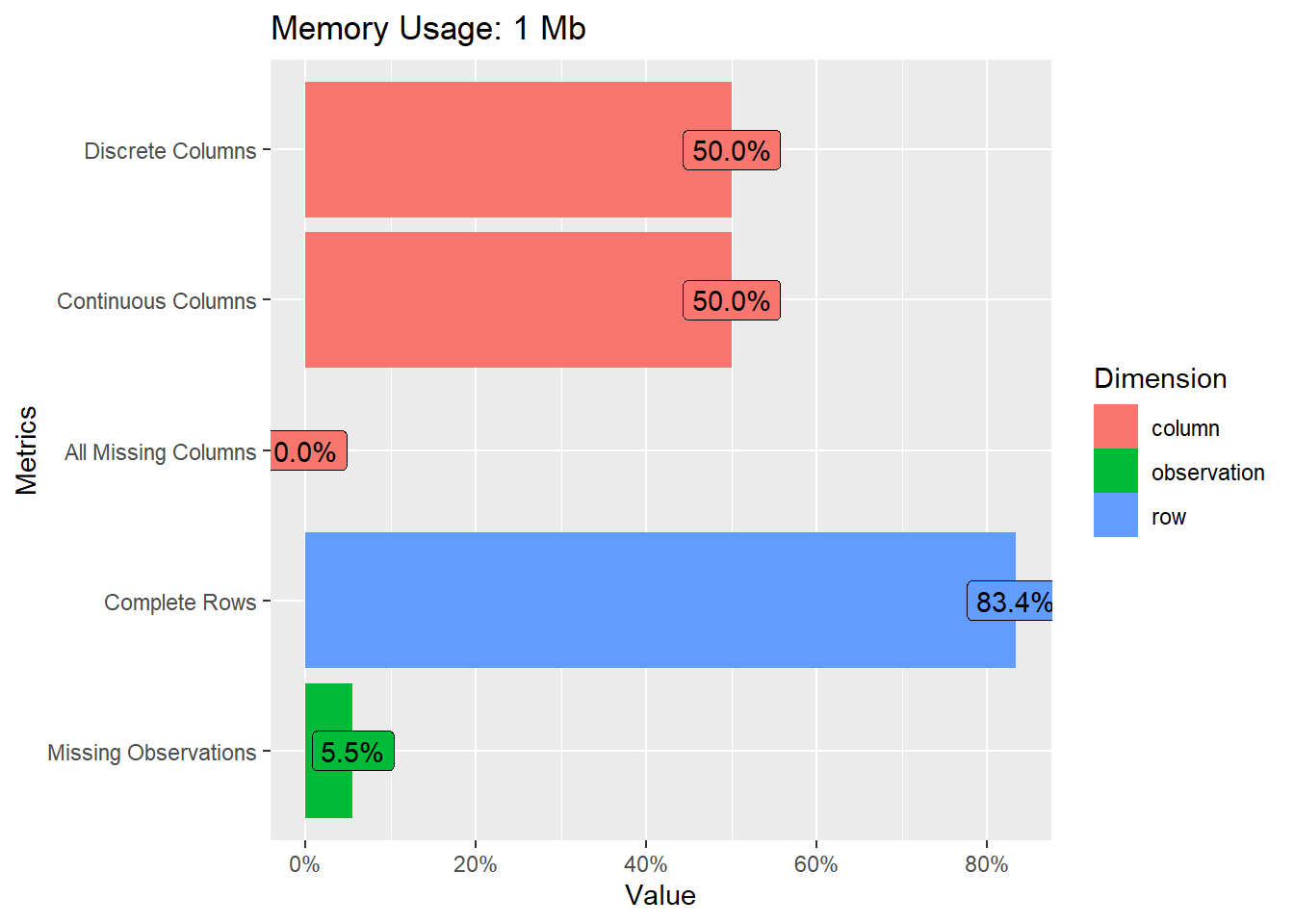
#plot_missing(viv_ancha)
#plot_bar(viv_ancha) # grafica de factores
plot_bar(viv_ancha,by = "t_finca") # grafica de un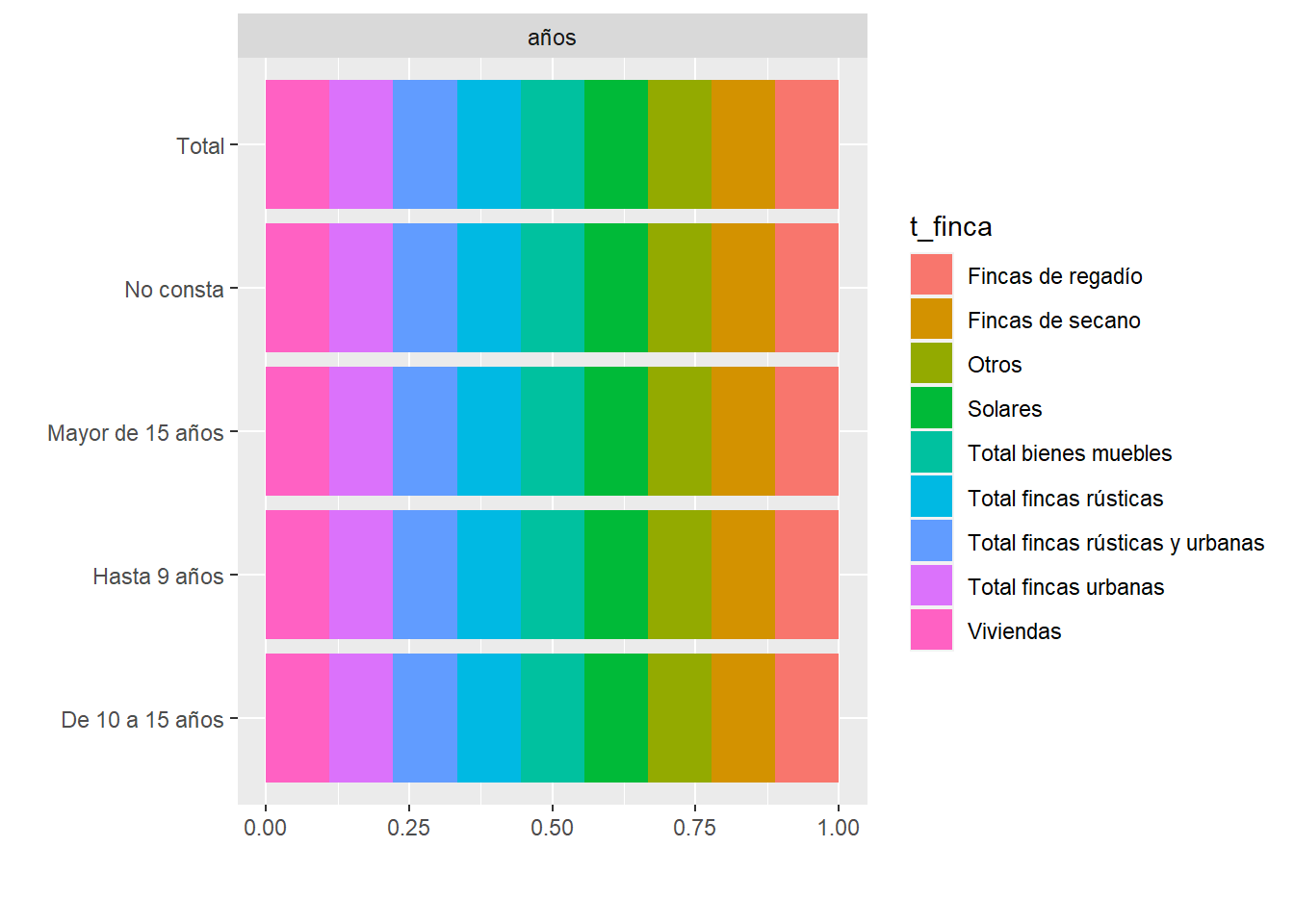
#plot_correlation(viv_ancha, maxcat = 5L) # correlacion de 5 primeras categorías
#plot_histogram(viv_ancha)Puedes encontrar más información de este paquete en:https://cran.r-project.org/web/packages/DataExplorer/vignettes/dataexplorer-intro.html
SmartEDA
Otra librería parecida es SmartEDA, con un funcionamiento similar a DataExplorer, aunque tiene una diferencias muy agradecida y es que escribe el código de cada gráfica o tabla en el informe. La función principal es ExpReport()
library(SmartEDA)
data<- airquality
# funcioin que genera un informa completo
ExpReport(data,op_file='informeEDA.html')
# si queremos alguna gráfica o tabla por separado
ExpData(data=data,type=1)
ExpData(data=data,type=2)
ExpNumStat(data,by="A",gp=NULL,Qnt=seq(0,1,0.1),MesofShape=2,Outlier=TRUE,round=2)
# una tabla resumen con multitud de estadisticos de las variables numericas
ExpNumStat(viv_ancha,by="A",gp=NULL,round=2)Esta es una imagen del informe de salida:

dlookr
Otra librería, para mi la mejor, para EDA es dlookr. Con una simple función nos genera un completísimo informe de los datos origen en formato página web.
Además tiene mil opciones de estadísticos, gráficas o transformaciones, incluso imputación de valores NA (relleno de datos).
Vamos a poner algunos simples ejemplos. Para generar el informe completo se usa la función diagnose_web_report() o eda_web_report() según el interés ultimo que buscamos.
library(dlookr)
library(dplyr)
#library(nycflights13)# Para los datos de ejemplo
eda_web_report(viv_ancha2)
diagnose_web_report(viv_ancha) # Una imagen del informe de salida es así:

dlookr imagen de informe salida
La librería tiene mil opciones de análisis y entre las funciones disponibles, aquí van algunos ejemplos:
library(dlookr)
library(dplyr)
diagnose(viv_ancha)## # A tibble: 6 x 6
## variables types missing_count missing_percent unique_count unique_rate
## <chr> <chr> <int> <dbl> <int> <dbl>
## 1 t_finca character 0 0 9 0.000377
## 2 provincia character 0 0 53 0.00222
## 3 años character 0 0 5 0.000210
## 4 periodo integer 0 0 10 0.000419
## 5 num_hipo numeric 3962 16.6 5027 0.211
## 6 import_hipo numeric 3968 16.6 12661 0.531describe(viv_ancha)## # A tibble: 3 x 26
## variable n na mean sd se_mean IQR skewness kurtosis p00
## <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 periodo 23850 0 1998. 2.87e0 1.86e-2 5 0 -1.22 1994
## 2 num_hipo 19888 3962 4004. 3.12e4 2.21e+2 1075. 18.2 381. 1
## 3 import_hipo 19882 3968 298010. 2.50e6 1.77e+4 85292. 22.4 619. 2
## # ... with 16 more variables: p01 <dbl>, p05 <dbl>, p10 <dbl>, p20 <dbl>,
## # p25 <dbl>, p30 <dbl>, p40 <dbl>, p50 <dbl>, p60 <dbl>, p70 <dbl>,
## # p75 <dbl>, p80 <dbl>, p90 <dbl>, p95 <dbl>, p99 <dbl>, p100 <dbl>normality(viv_ancha)## # A tibble: 3 x 4
## vars statistic p_value sample
## <chr> <dbl> <dbl> <dbl>
## 1 periodo 0.936 6.93e-42 5000
## 2 num_hipo 0.100 1.13e-88 5000
## 3 import_hipo 0.105 1.52e-88 5000plot_normality(viv_ancha)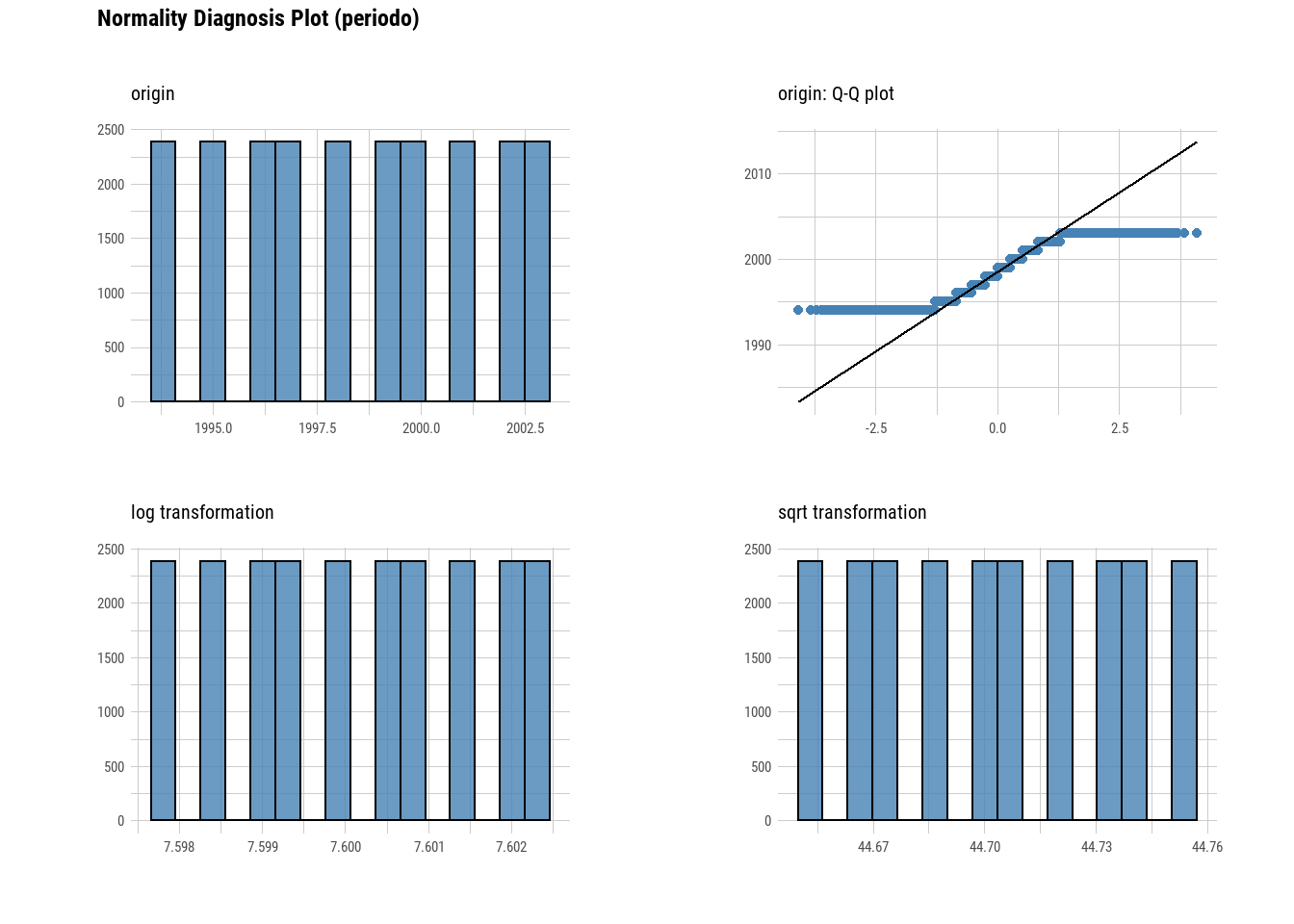
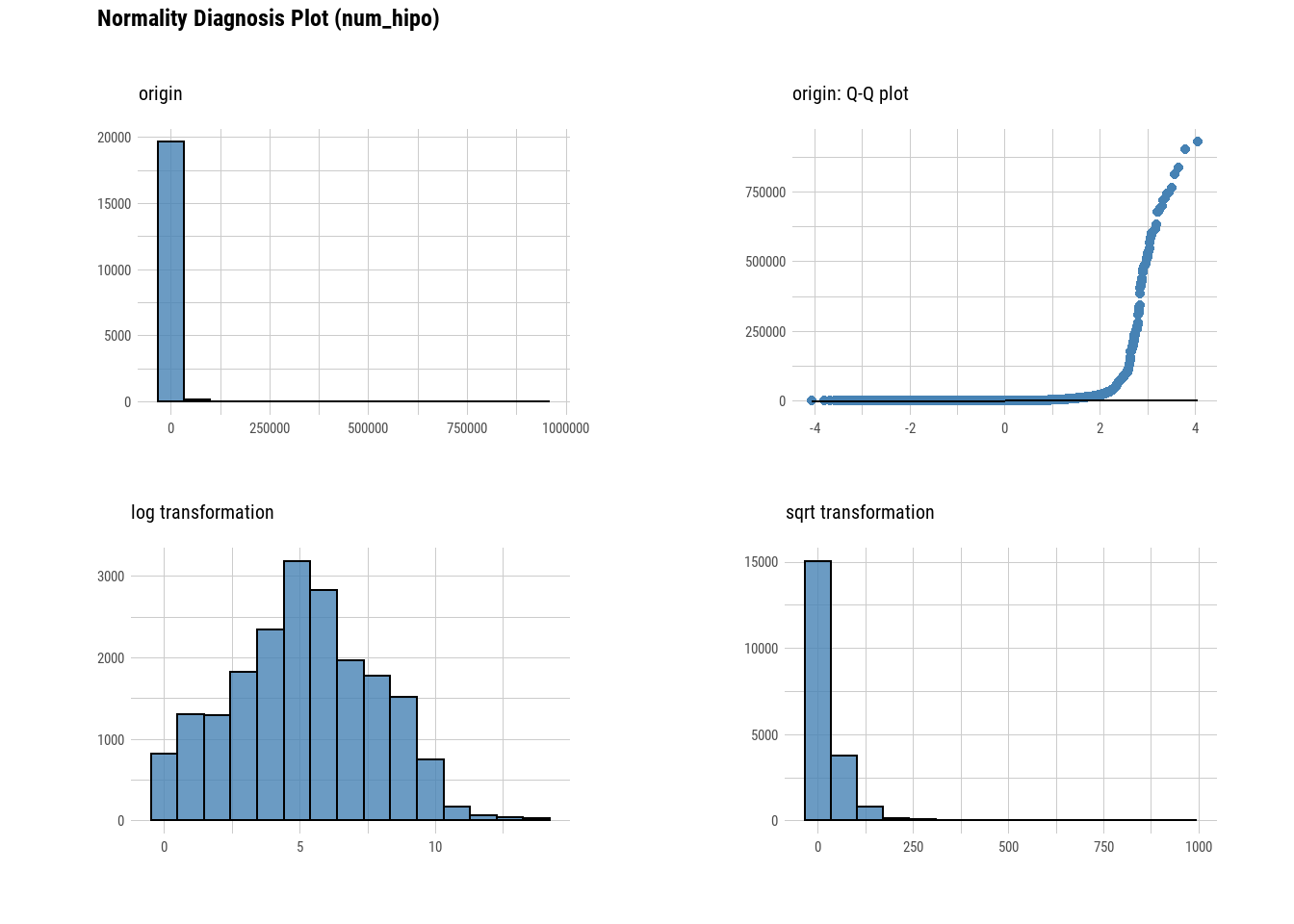
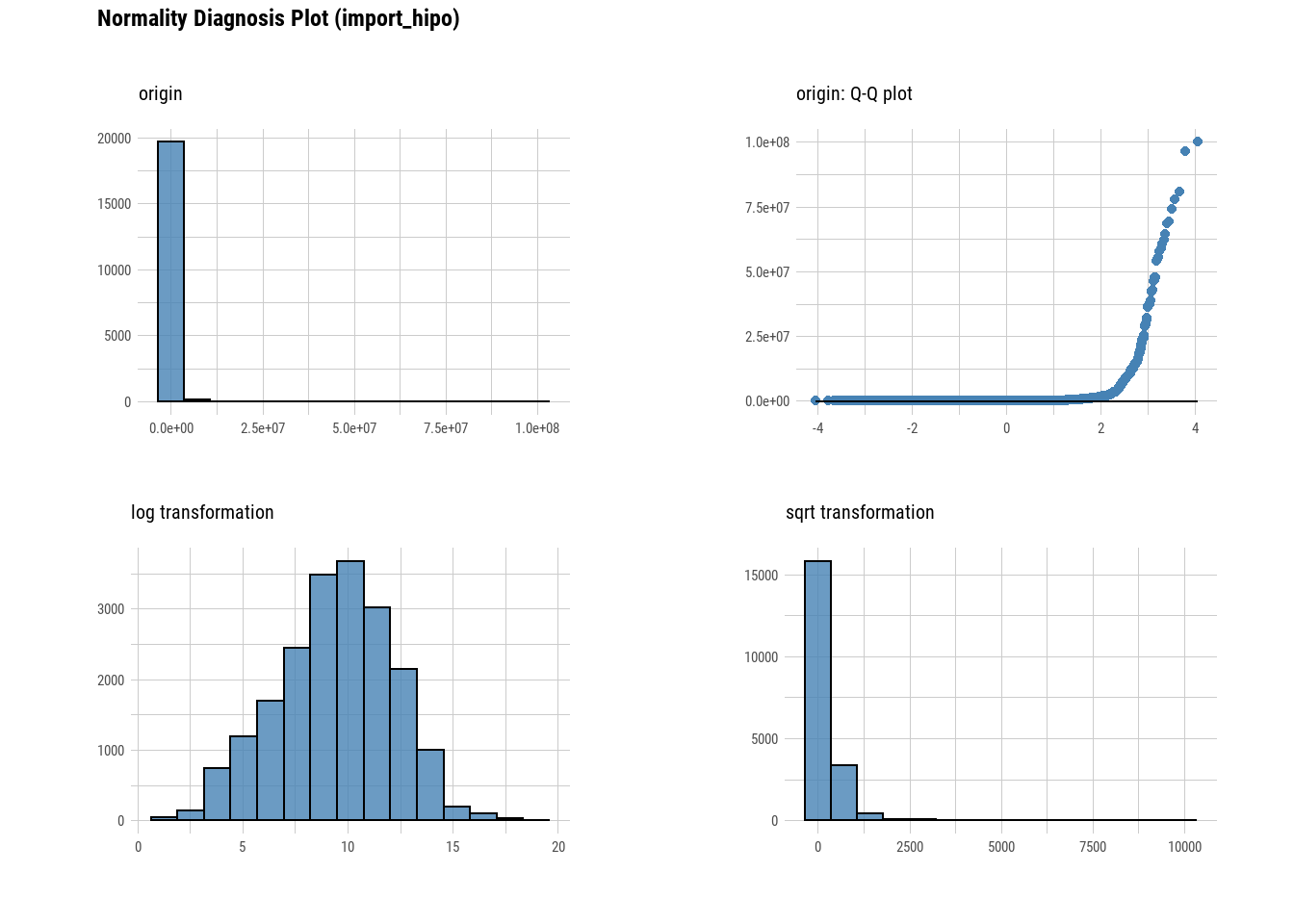
plot_correlate(viv_ancha)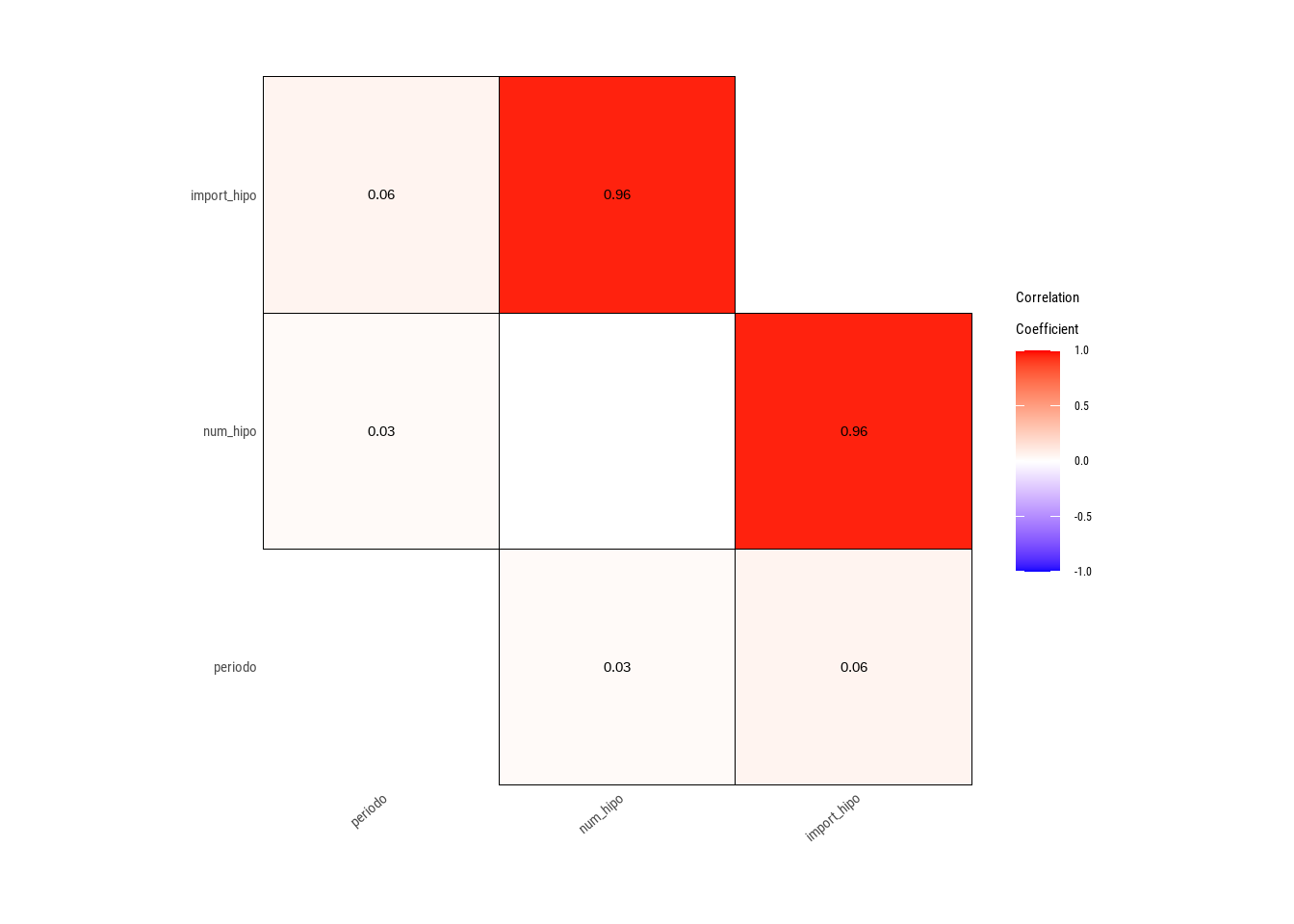
Recomendamos leer su web y la descripción de las funciones al detalle para sacar partido a esta maravilla.
